LangGraph-1-introdiction
Contents
LangGraph 是一个基于图结构的框架,用于构建多智能体(Multi-Agent)系统。它通过图(Graph)来定义智能体之间的交互逻辑和控制流,解决了传统链式(Chain-of-Thought)框架在处理复杂任务时的局限性,例如条件判断、循环、分支和中断等。
1.LangGraph
什么是 LangGraph?
LangGraph 是一个基于图结构的框架,用于构建多智能体(Multi-Agent)系统。它通过图(Graph)来定义智能体之间的交互逻辑和控制流,解决了传统链式(Chain-of-Thought)框架在处理复杂任务时的局限性,例如条件判断、循环、分支和中断等。
LangGraph 与 LangChain 的核心区别:
- LangChain:基于链式结构,适合线性任务流程。
- LangGraph:基于图结构,支持非线性、多路径的控制流,更适合复杂的智能体协作场景。
- LangGraph 扩展了 LangChain 的能力,允许更灵活的智能体调度和状态管理。
什么是图(Graph)?
在LangGraph中,图是一种计算结构,将agent的工作流建模为有向图。该图使用三个关键组件定义Agent的行为:状态(共享数据结构)、节点(编码逻辑的Python函数)和边(确定执行流的函数)。
在LangGraph中,主要的图实现是StateGraph类,这是一个特殊的图,其中节点通过读写共享状态进行通信。
2.Graph核心概念
State
State是图(Graph)中传递的信息,是一个共享的数据结构(State Schema),它代表了你的应用程序的当前快照。它可以是任何Python类型,但通常是一个TypedDict或者Pydantic的BaseModel。
from typing_extensions import TypedDict
class State(TypedDict):
graph_state: str
TypedDict
TypedDict 是 Python 的一个类型注解工具,用于定义一个字典的结构,指定字典中每个键的类型。它通常用于静态类型检查,帮助开发者更好地理解代码的结构,同时也能让工具(如类型检查器)在开发阶段发现潜在的错误。
如果是开发ChatBot应用,LangGraph内置了MessagesState类型可以直接使用,替代自定义的State,它是一个包含消息列表的字典。每个消息可以是:
- 用户消息(HumanMessage):用户输入的内容。
- AI 消息(AIMessage):语言模型生成的响应。
- 工具调用消息(ToolMessage):工具调用的请求或响应。
每条消息都可以附加一些内容:
content- 消息的内容name- 可选,消息的作者response_metadata- 可选,一个包含元数据的字典(例如,通常由 AIMessage 的提供者填充)
Nodes
节点 实质上就是 Python 函数。其第一个位置参数就是上述所定义的状态。因为该状态是一个按照上述定义所设定的TypedDict(“类型字典”),所以每个节点都可以通过 state['graph_state'] 来访问键graph_state。每个节点都会返回状态键graph_state的新值。默认情况下,每个节点返回的新值会覆盖 之前的状态值。
def node_1(state):
print("---Node 1---")
return {"graph_state": state['graph_state'] +" I am"}
def node_2(state):
print("---Node 2---")
return {"graph_state": state['graph_state'] +" happy!"}
def node_3(state):
print("---Node 3---")
return {"graph_state": state['graph_state'] +" sad!"}
节点是图的基本单元,每个节点可以执行一个特定的操作。在代码中,节点可以是:
- 语言模型(Chat Models):例如
ChatOpenAI,它可以处理输入的对话消息并生成响应。 - 工具调用(Tool Calls):例如
multiply函数,它可以执行特定的计算任务。 - 自定义函数:用户可以定义自己的函数作为节点,例如
tool_calling_llm,它调用语言模型并处理工具调用。
Edges
Edges 用于连接节点,定义了信息在节点之间的流动路径。如果你的需求是始终从例如“节点 1”前往“节点 2”,则应使用常规边。条件边 用于满足您希望在节点之间“可选地”进行路径规划的需求。条件边是以函数的形式实现的,这些函数会根据一定的逻辑来返回接下来要访问的节点。
import random
from typing import Literal
def decide_mood(state) -> Literal["node_2", "node_3"]:
# Often, we will use state to decide on the next node to visit
user_input = state['graph_state']
# Here, let's just do a 50 / 50 split between nodes 2, 3
if random.random() < 0.5:
# 50% of the time, we return Node 2
return "node_2"
# 50% of the time, we return Node 3
return "node_3"
图的构建
现在,我们将根据上述定义的组件来构建图形。StateGraph 类就是我们可以使用的图类。
-
首先,我们使用上述定义的“State”类来初始化一个“StateGraph”。然后,我们添加节点和边。
- 起始节点,这是一种特殊的节点,该节点会将用户输入发送至图中,以此来指示我们从何处开始构建图。
- 结束节点是一种特殊的节点,用于表示终端节点。
- 最后,我们会对我们的图进行编译,以对图的结构进行一些基本的检查。
- 我们可以将该图可视化为一个Mermaid图。
from IPython.display import Image, display
from langgraph.graph import StateGraph, START, END
# Build graph
builder = StateGraph(State)
builder.add_node("node_1", node_1)
builder.add_node("node_2", node_2)
builder.add_node("node_3", node_3)
# Logic
builder.add_edge(START, "node_1")
builder.add_conditional_edges("node_1", decide_mood) #自选函数,执行分支切换,跳转到不同节点node
builder.add_edge("node_2", END)
builder.add_edge("node_3", END)
# Add
graph = builder.compile()
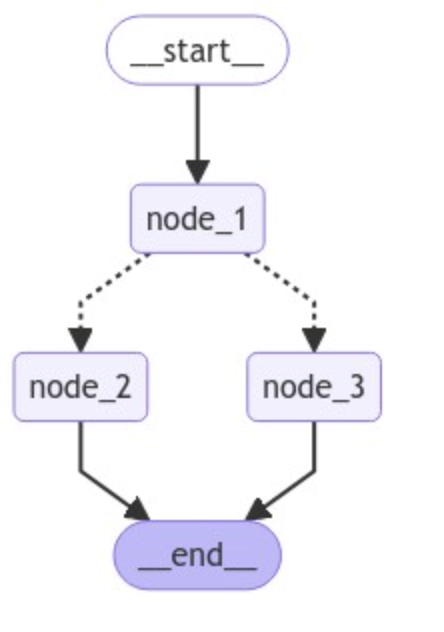
图的可视化(Graph Visualization)
代码中使用了 langgraph.graph 和 IPython.display 来可视化图的结构。例如:
display(Image(graph.get_graph().draw_mermaid_png()))
这会生成一个可视化的图,展示节点和边的连接关系。
状态更新(State Update)
在图的执行过程中,状态可能会被更新。为了确保状态的更新符合预期,可以使用 reducer 函数。
在ChatBot对话过程中,消息需要不断追加到历史记录中,而不是覆盖之前的记录。使用MessagesState 时通过使用 add_messages 这个 reducer 函数来实现这一点。add_messages 确保新的消息被追加到现有的消息列表中,而不是替换掉之前的列表。
这种机制保证了对话历史的完整性,使得模型在后续的对话中能够参考完整的上下文。
from typing import Annotated
from langgraph.graph.message import add_messages
class MessagesState(TypedDict):
messages: Annotated[list[AnyMessage], add_messages]
-
TypedDict 是 Python 的一个类型注解工具,用于定义一个字典的结构,指定字典中每个键的类型。它通常用于静态类型检查,帮助开发者更好地理解代码的结构,同时也能让工具(如类型检查器)在开发阶段发现潜在的错误。
-
MessagesState 是一个继承自 TypedDict 的类,它定义了一个特定的字典结构。这个字典结构包含一个键 messages,其值是一个列表,列表中的每个元素都是 AnyMessage 类型的对象。
-
Annotated 是 Python 的一个类型注解工具,用于为类型添加元数据。在这里,Annotated 被用来为 messages 字段添加一个元数据 add_messages。
-
list[AnyMessage]
-
list 表示这是一个列表。
-
AnyMessage 是一个类型,表示列表中的每个元素都是 AnyMessage 类型的对象。AnyMessage 是一个通用的消息类型,可能包含多种不同类型的消息(如 HumanMessage、AIMessage 等)。
-
-
add_messages 是一个函数,作为元数据被添加到 messages 字段中。它的作用是定义如何更新 messages 字段的值。具体来说,add_messages 是一个 reducer 函数,用于将新的消息追加到现有的消息列表中,而不是覆盖它。
工具调用(Tool Calls)
工具调用允许语言模型与外部系统(如 API)交互。在代码中,工具调用通过 bind_tools 方法绑定到语言模型上。例如:
llm_with_tools = llm.bind_tools([multiply])
当语言模型认为需要调用工具时,它会生成一个工具调用请求,其中包含工具的名称和参数。
图形调用
- 所编译的图表实现了可运行协议。这提供了一种执行 LangChain 组件的标准方法。
- 图的执行是指从
START节点开始,按照边的定义顺序,依次执行每个节点的操作,直到到达END节点。 invoke是该接口中的一个标准方法。输入是一个字典{"graph_state": "Hi, this is lance."}",它为我们的图状态字典设定了初始值。当调用invoke时,图会从START节点开始执行。它会按照规定的节点(“节点 1”、“节点 2”、“节点 3”)的顺序进行推进。 该条件边将根据 50/50 的决策规则从节点“1”通向节点“2”或“3”。- 每个节点函数都会接收当前状态,并返回一个新的值,该值会覆盖整个图的状态。
- 执行过程会一直进行,直到到达
END节点为止。
graph.invoke({"graph_state" : "Hi, this is Lance."})
---Node 1---
---Node 3---
{'graph_state': 'Hi, this is Lance. I am sad!'}
invoke会同步运行整个图。这一过程会等待每一步骤完成后再进行下一步操作。它会返回所有节点执行完毕后图的最终状态。在这种情况下,它会返回“节点 3”完成后的状态:
{'graph_state': 'Hi, this is Lance. I am sad!'}
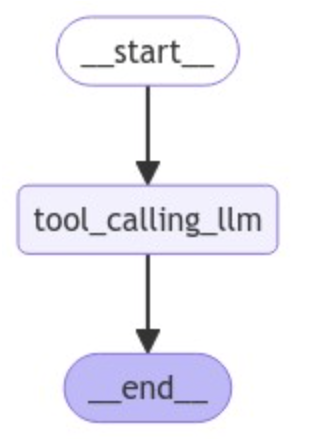
完整代码
mudule1/concept.py
from langgraph.graph import MessagesState
from langchain_openai import ChatOpenAI
from IPython.display import Image, display
from langgraph.graph import StateGraph, START, END
from langchain_core.messages import HumanMessage
import common.customModel
llm = common.customModel.volcengine_doubao15pro32k()
def multiply(a: int, b: int) -> int:
"""Multiply a and b.
Args:
a: first int
b: second int
"""
return a * b
llm_with_tools = llm.bind_tools([multiply])
# Node
def tool_calling_llm(state: MessagesState):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
# Build graph
builder = StateGraph(MessagesState)
builder.add_node("tool_calling_llm", tool_calling_llm)
builder.add_edge(START, "tool_calling_llm")
builder.add_edge("tool_calling_llm", END)
graph = builder.compile()
messages = graph.invoke({"messages": HumanMessage(content="Multiply 2 and 3")})
for m in messages['messages']:
m.pretty_print()
# View
#display(Image(graph.get_graph().draw_mermaid_png()))
================================ Human Message =================================
Multiply 2 and 3
================================== Ai Message ==================================
Tool Calls:
multiply (call_acd9804ff8504f5797b6bf)
Call ID: call_acd9804ff8504f5797b6bf
Args:
a: 2
b: 3
3.Agent 架构
大型语言模型(LLM)应用通常会在调用LLM之前和/或之后实施特定的控制流程步骤。以RAG(Retrieval-Augmented Generation)为例,它会检索与用户问题相关的文档,然后将这些文档传递给LLM,以便使模型的回答基于提供的文档上下文。
我们有时不希望硬编码固定的控制流,而是希望 LLM 系统能够自行选择控制流来解决更复杂的问题!这是 agent 的一个定义:agent 是一个使用 LLM 来决定应用程序控制流的系统。LLM 可以通过多种方式控制应用程序
- LLM 可以在两个潜在路径之间进行路由
- LLM 可以决定调用众多工具中的哪一个
- LLM 可以决定生成的答案是否足够,或者是否需要更多工作
因此,有许多不同类型的agent 架构,它们赋予 LLM 不同程度的控制权。
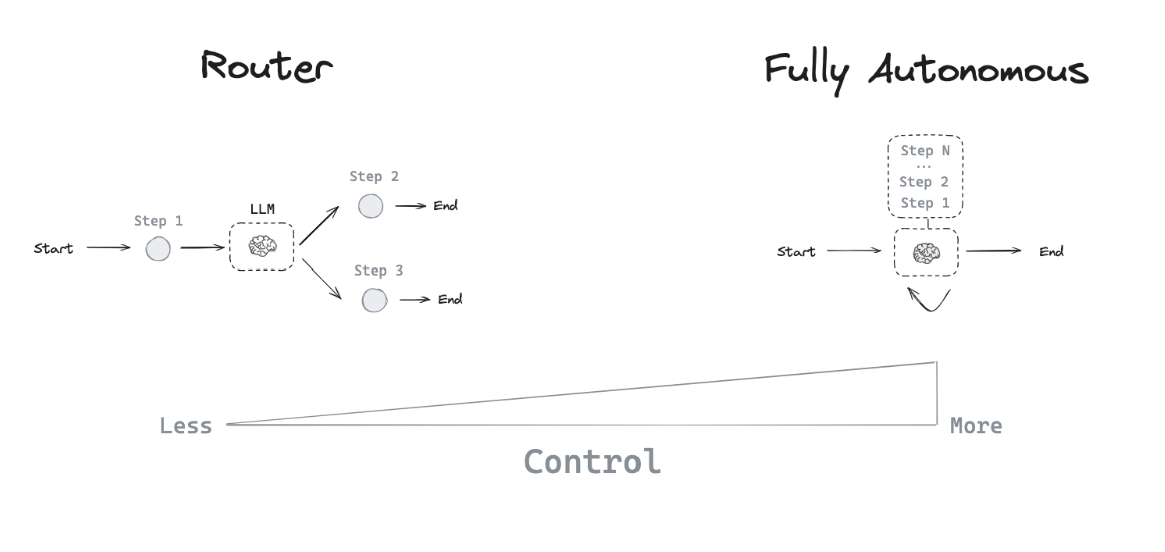
主要的Agent架构三种:
- Router:路由器允许 LLM 从指定的选项集中选择一个步骤。这种 agent 架构的控制级别相对有限,因为 LLM 通常只专注于做出一个决策,并从有限的预定义选项集中生成特定输出。路由器通常采用几种不同的概念来实现此目的。
- 工具调用 Agent:虽然路由器允许 LLM 做出一个决策,但更复杂的 agent 架构通过两种关键方式扩展了 LLM 的控制
- 多步决策:LLM 可以连续做出一系列决策,而不仅仅是一个决策。
- 工具访问:LLM 可以选择并使用各种工具来完成任务。
- 定制 agent 架构:利用外部代理基础设施,同时专注于构建独特且特定于应用的认知架构,以实现差异化竞争优势。
4.Router
通过一个具体实例解释一个路由架构:聊天模型根据用户输入决定直接响应还是调用工具。为了使图能够处理两种输出,提出了添加调用工具的节点和添加基于聊天模型输出的条件边两个想法。
mudule1/router.py
from langgraph.graph import MessagesState
from langchain_openai import ChatOpenAI
from IPython.display import Image, display
from langgraph.graph import StateGraph, START, END
from langchain_core.messages import HumanMessage
from langgraph.prebuilt import ToolNode
from langgraph.prebuilt import tools_condition
def multiply(a: int, b: int) -> int:
"""Multiply a and b.
Args:
a: first int
b: second int
"""
return a * b
import common.customModel
llm = common.customModel.volcengine_doubao15pro32k()
llm_with_tools = llm.bind_tools([multiply])
# Node
def tool_calling_llm(state: MessagesState):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
# Build graph
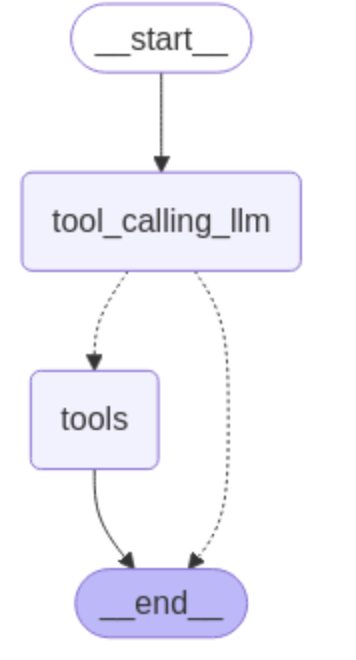
builder = StateGraph(MessagesState)
builder.add_node("tool_calling_llm", tool_calling_llm)
builder.add_node("tools", ToolNode([multiply]))
builder.add_edge(START, "tool_calling_llm")
builder.add_conditional_edges(
"tool_calling_llm",
# If the latest message (result) from assistant is a tool call -> tools_condition routes to tools
# If the latest message (result) from assistant is a not a tool call -> tools_condition routes to END
tools_condition,
)
builder.add_edge("tools", END)
graph = builder.compile()
# View
# display(Image(graph.get_graph().draw_mermaid_png()))
messages = [HumanMessage(content="Hello, what is 2 multiplied by 2?")]
messages = graph.invoke({"messages": messages})
for m in messages['messages']:
m.pretty_print()
================================ Human Message =================================
Hello, what is 2 multiplied by 2?
================================== Ai Message ==================================
Tool Calls:
multiply (call_c9ba4fe710c9496687a1d7)
Call ID: call_c9ba4fe710c9496687a1d7
Args:
a: 2
b: 2
================================= Tool Message =================================
Name: multiply
4
重点
builder.add_conditional_edges(
"tool_calling_llm",
# If the latest message (result) from assistant is a tool call -> tools_condition routes to tools
# If the latest message (result) from assistant is a not a tool call -> tools_condition routes to END
tools_condition,
)
其中tools_condition是LangGraph的内置函数,实现了llm工具调用的选择
tools_condition(
state: Union[
list[AnyMessage], dict[str, Any], BaseModel
],
messages_key: str = "messages",
) -> Literal["tools", "__end__"]
在条件边(add_conditional_edges)中使用,如果最后一条消息(last message)有工具调用(tool calls),就路由到工具节点(ToolNode);如果没有工具调用,就路由到结束(end)。
5.Agent
在前面提到的路由器中,我们调用了模型,若其决定调用工具,我们便向用户返回了一个工具消息(ToolMessage)。
然而,要是我们直接把那个工具消息(ToolMessage)重新传回给模型呢?模型可以基于此选择(1)调用另一个工具,或者(2)直接作出回应。
这便是 ReAct 这一通用代理架构背后的构思。
- act(行动):让模型调用特定的工具。
- observe(观察):把工具的输出结果传递回模型。
- reason(推理):让模型对工具的输出进行推理,以决定下一步该做什么(例如,是调用另一个工具,还是直接进行回应)。
这种通用型架构能够适用于多种类型的工具。
- 智能体规划和推理的概念 规划和推理涉及大型语言模型思考应采取何种行动的能力,包括短期和长期步骤。模型需评估所有可用信息,决定采取哪些步骤以及当前应执行的步骤。
- 目前面临的挑战 函数调用虽可让代理选择立即执行的操作,但完成复杂任务需按顺序采取一系列行动,这对语言模型来说较难。一方面,模型需考虑长远目标,又要跳回短期行动;另一方面,随着行动增加,上下文窗口扩大,可能导致模型分心,表现不佳。
- 改进智能体规划的方法 最简单直接的办法是确保语言模型拥有进行合理推理/规划所需的所有信息,增加检索步骤或明确提示指令可作为改进措施。此外,可尝试改变应用程序的认知架构,包括通用认知架构和特定领域认知架构。
- 通用认知架构与特定领域认知架构 通用认知架构试图实现更广泛的通用推理能力,如“规划与求解”架构和“反思”架构,但往往过于笼统,难以实际应用于生产中的代理。相反,基于特定领域的认知架构构建的代理更为常见,如《AlphaCodium》论文中的“流程工程”,其流程对所解决的问题具有很强的针对性。
- 特定领域认知架构的作用 一方面,可将此视为向代理传达其应执行操作的另一种方式,可通过提示指令传达,也可在代码中硬编码特定转换;另一方面,这实际上是把规划的责任从 LLM 转移到工程师身上,让工程师为 LLM 做规划。
- 未来规划和推理的发展趋势 通用推理将越来越多地融入模型层,模型会变得越来越智能、快速且便宜,向其传递大量上下文信息将变得越来越可行。但无论模型变得多么强大,始终需要以某种形式向代理传达它应该做什么,提示和自定义架构会一直存在。对于简单任务,提示可能足够;对于复杂任务,代码优先的方法可能更好。
module1/agent.py
from langchain_openai import ChatOpenAI
from langchain_core.runnables.graph_mermaid import MermaidDrawMethod
def multiply(a: int, b: int) -> int:
"""Multiply a and b.
Args:
a: first int
b: second int
"""
return a * b
# This will be a tool
def add(a: int, b: int) -> int:
"""Adds a and b.
Args:
a: first int
b: second int
"""
return a + b
def divide(a: int, b: int) -> float:
"""Divide a and b.
Args:
a: first int
b: second int
"""
return a / b
tools = [add, multiply, divide]
import common.customModel
llm = common.customModel.volcengine_doubao15pro32k()
llm_with_tools = llm.bind_tools(tools, parallel_tool_calls=False)
from langgraph.graph import MessagesState
from langchain_core.messages import HumanMessage, SystemMessage
# System message
sys_msg = SystemMessage(content="You are a helpful assistant tasked with performing arithmetic on a set of inputs.")
# Node
def assistant(state: MessagesState):
return {"messages": [llm_with_tools.invoke([sys_msg] + state["messages"])]}
from langgraph.graph import START, StateGraph
from langgraph.prebuilt import tools_condition
from langgraph.prebuilt import ToolNode
from IPython.display import Image, display
# Graph
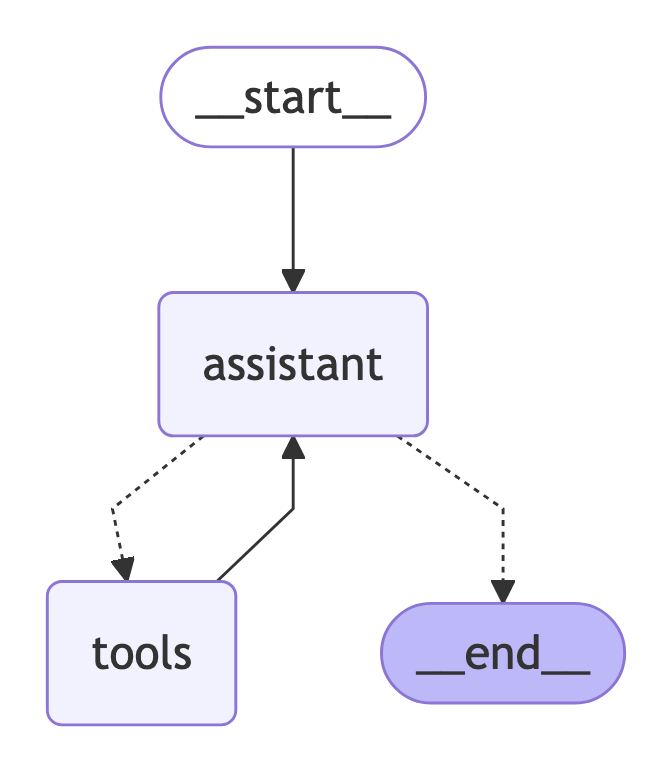
builder = StateGraph(MessagesState)
# Define nodes: these do the work
builder.add_node("assistant", assistant)
builder.add_node("tools", ToolNode(tools))
# Define edges: these determine how the control flow moves
builder.add_edge(START, "assistant")
builder.add_conditional_edges(
"assistant",
# If the latest message (result) from assistant is a tool call -> tools_condition routes to tools
# If the latest message (result) from assistant is a not a tool call -> tools_condition routes to END
tools_condition,
)
builder.add_edge("tools", "assistant")
react_graph = builder.compile()
# Show
import common.render
common.render.renderGraph(react_graph)
messages = [HumanMessage(content="Add 3 and 4. Multiply the output by 2. Divide the output by 5")]
messages = react_graph.invoke({"messages": messages})
for m in messages['messages']:
m.pretty_print()
================================ Human Message =================================
Add 3 and 4. Multiply the output by 2. Divide the output by 5
================================== Ai Message ==================================
Tool Calls:
add (call_7f77261e98fd425f9855ea)
Call ID: call_7f77261e98fd425f9855ea
Args:
a: 3
b: 4
================================= Tool Message =================================
Name: add
7
================================== Ai Message ==================================
Tool Calls:
multiply (call_8a55f13ca9ec43b28701bb)
Call ID: call_8a55f13ca9ec43b28701bb
Args:
a: 7
b: 2
================================= Tool Message =================================
Name: multiply
14
================================== Ai Message ==================================
Tool Calls:
divide (call_a7b4dfdd695c4bbf9561ea)
Call ID: call_a7b4dfdd695c4bbf9561ea
Args:
a: 14
b: 5
================================= Tool Message =================================
Name: divide
2.8
================================== Ai Message ==================================
The final result after performing the operations (adding 3 and 4, then multiplying by 2, and finally dividing by 5) is 2.8.
6.Agent-Memory
记忆对于 agent 至关重要,它使 agent 能够在多步问题解决过程中保留和利用信息。它在不同尺度上运作
- 短期记忆:允许 agent 访问在序列早期步骤中获取的信息。
- 长期记忆:使 agent 能够回忆起先前交互中的信息,例如对话中的历史消息。
LangGraph 提供对记忆实现的完全控制
State:用户定义的模式,指定要保留的记忆的精确结构。Checkpointers:一种机制,用于在不同交互的每个步骤中存储状态。
本节讨论短期记忆的实现:Checkpointers。
module1/agent-memory.py
from langchain_openai import ChatOpenAI
def multiply(a: int, b: int) -> int:
"""Multiply a and b.
Args:
a: first int
b: second int
"""
return a * b
# This will be a tool
def add(a: int, b: int) -> int:
"""Adds a and b.
Args:
a: first int
b: second int
"""
return a + b
def divide(a: int, b: int) -> float:
"""Divide a and b.
Args:
a: first int
b: second int
"""
return a / b
tools = [add, multiply, divide]
import common.customModel
llm = common.customModel.volcengine_doubao15pro32k()
llm_with_tools = llm.bind_tools(tools)
from langgraph.graph import MessagesState
from langchain_core.messages import HumanMessage, SystemMessage
# System message
sys_msg = SystemMessage(content="You are a helpful assistant tasked with performing arithmetic on a set of inputs.")
# Node
def assistant(state: MessagesState):
return {"messages": [llm_with_tools.invoke([sys_msg] + state["messages"])]}
from langgraph.graph import START, StateGraph
from langgraph.prebuilt import tools_condition, ToolNode
from IPython.display import Image, display
# Graph
builder = StateGraph(MessagesState)
# Define nodes: these do the work
builder.add_node("assistant", assistant)
builder.add_node("tools", ToolNode(tools))
# Define edges: these determine how the control flow moves
builder.add_edge(START, "assistant")
builder.add_conditional_edges(
"assistant",
# If the latest message (result) from assistant is a tool call -> tools_condition routes to tools
# If the latest message (result) from assistant is a not a tool call -> tools_condition routes to END
tools_condition,
)
builder.add_edge("tools", "assistant")
react_graph = builder.compile()
前面几乎与上一节一致,接下来,继续
messages = [HumanMessage(content="Add 3 and 4.")]
messages = react_graph.invoke({"messages": messages})
for m in messages['messages']:
m.pretty_print()
输出
================================ Human Message =================================
Add 3 and 4.
================================== Ai Message ==================================
Tool Calls:
add (call_zZ4JPASfUinchT8wOqg9hCZO)
Call ID: call_zZ4JPASfUinchT8wOqg9hCZO
Args:
a: 3
b: 4
================================= Tool Message =================================
Name: add
7
================================== Ai Message ==================================
The sum of 3 and 4 is 7.
现在继续乘2
messages = [HumanMessage(content="Multiply that by 2.")]
messages = react_graph.invoke({"messages": messages})
for m in messages['messages']:
m.pretty_print()
输出
================================ Human Message =================================
Multiply that by 2.
================================== Ai Message ==================================
Tool Calls:
multiply (call_prnkuG7OYQtbrtVQmH2d3Nl7)
Call ID: call_prnkuG7OYQtbrtVQmH2d3Nl7
Args:
a: 2
b: 2
================================= Tool Message =================================
Name: multiply
4
================================== Ai Message ==================================
The result of multiplying 2 by 2 is 4.
结果没有保留我们初次聊天时提到的“7”这个数字的记忆!这是因为状态对于单个图执行过程而言是暂时性的。因此,这限制了我们进行多轮对话时不受打断干扰的能力。
此时,Checkpointers出场可以来解决这个问题:
- LangGraph 能够利用检查点器在每一步操作完成后自动保存图的状态。这种内置的持久化层为我们提供了内存支持,使得 LangGraph 能够从上次的状态更新处继续执行。
- 使用起来最为简便的检查器之一便是 MemorySaver,它是一款用于存储图状态的内存型键值存储器。我们所需要做的仅仅是用检查点器来编译这个图,这样我们的图就有了内存了!
from langgraph.checkpoint.memory import MemorySaver
memory = MemorySaver()
react_graph_memory = builder.compile(checkpointer=memory)
- 当我们使用内存时,需要指定一个 thread_id 。
- 这个 thread_id 将用于存储我们所收集的图态集合。
这里有一幅示意图:
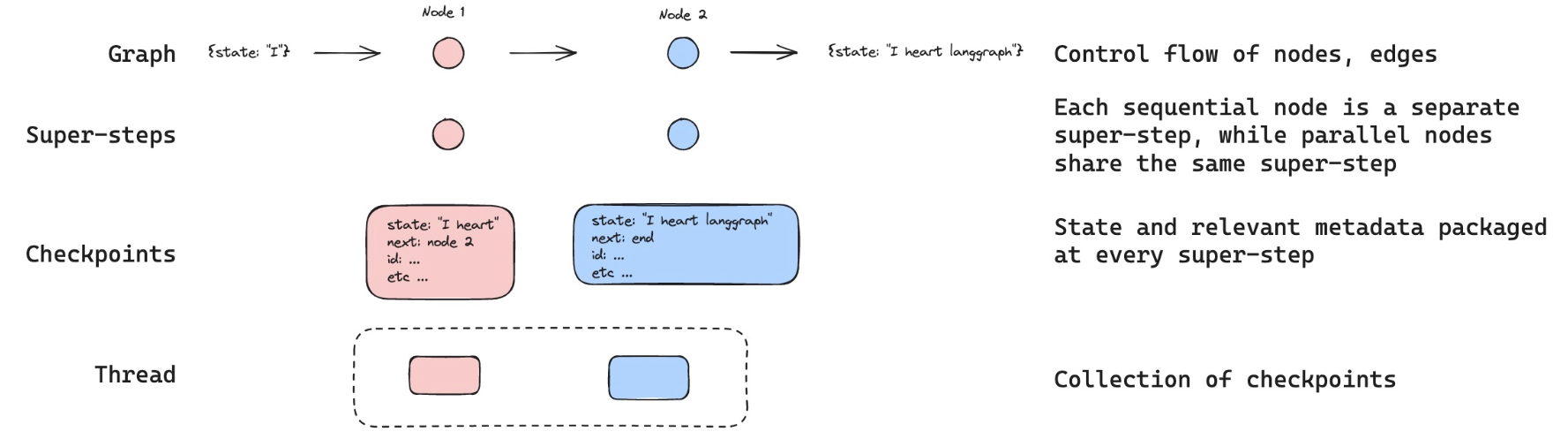
- checkpointer会在图的每一步中记录状态
- 这些检查点checkpointer被保存在一个线程中
- 我们可以在未来通过thread_id 访问该线程
# Specify a thread
config = {"configurable": {"thread_id": "1"}}
# Specify an input
messages = [HumanMessage(content="Add 3 and 4.")]
# Run
messages = react_graph_memory.invoke({"messages": messages},config)
for m in messages['messages']:
m.pretty_print()
================================ Human Message =================================
Add 3 and 4.
================================== Ai Message ==================================
Tool Calls:
add (call_MSupVAgej4PShIZs7NXOE6En)
Call ID: call_MSupVAgej4PShIZs7NXOE6En
Args:
a: 3
b: 4
================================= Tool Message =================================
Name: add
7
================================== Ai Message ==================================
The sum of 3 and 4 is 7.
如果我们传递相同的 thread_id,那么我们就可以从之前记录的状态检查点继续执行!
在这种情况下,上述对话被收录在该thread里。
我们传递的“HumanMessage”("Multiply that by 2.")被附加到了上述对话中。
所以,这个模型现在明白了that指的是“3 加 4 的和是 7”。
messages = [HumanMessage(content="Multiply that by 2.")]
messages = react_graph_memory.invoke({"messages": messages}, config)
for m in messages['messages']:
m.pretty_print()
================================ Human Message =================================
Add 3 and 4.
================================== Ai Message ==================================
Tool Calls:
add (call_MSupVAgej4PShIZs7NXOE6En)
Call ID: call_MSupVAgej4PShIZs7NXOE6En
Args:
a: 3
b: 4
================================= Tool Message =================================
Name: add
7
================================== Ai Message ==================================
The sum of 3 and 4 is 7.
================================ Human Message =================================
Multiply that by 2.
================================== Ai Message ==================================
Tool Calls:
multiply (call_fWN7lnSZZm82tAg7RGeuWusO)
Call ID: call_fWN7lnSZZm82tAg7RGeuWusO
Args:
a: 7
b: 2
================================= Tool Message =================================
Name: multiply
14
================================== Ai Message ==================================
The result of multiplying 7 by 2 is 14.
从而得到预期的正确结果。