LangGraph-2-state and memory
Contents
我们将逐步深入 LangGraph 的核心功能,从状态模式的定义到归并函数的使用,从消息处理到多模式数据的支持,再到内存管理和线程化对话的实现。通过一系列的代码示例和实际应用场景,展示 LangGraph 如何帮助开发者解决实际问题。
State Schema
Schema
- 当我们定义一个 LangGraph StateGraph 时,我们会使用一个Schema状态模型。
- 状态模型描绘了我们的图所将使用的数据的结构和类型。
- 所有的节点之间都使用这个状态模型进行通信。
- LangGraph 在定义状态模型方面提供了灵活性,能够兼容多种 Python 类型和验证方式!
TypedDict
- 正如我们在第1模块提到的,我们可以使用Python的typing模块中的TypedDict类。它允许你指定键以及它们对应的值类型。
- 但是,需要注意的是,这些是类型提示。它们可以被静态类型检查器(如mypy)或集成开发环境(IDE)用来在代码运行之前捕捉潜在的类型相关错误。但是它们在运行时不会被强制执行!
module2/TypedDict.py
from typing import Literal
class TypedDictState(TypedDict):
name: str
mood: Literal["happy","sad"]
import random
from IPython.display import Image, display
from langgraph.graph import StateGraph, START, END
def node_1(state):
print("---Node 1---")
return {"name": state['name'] + " is ... "}
def node_2(state):
print("---Node 2---")
return {"mood": "happy"}
def node_3(state):
print("---Node 3---")
return {"mood": "sad"}
def decide_mood(state) -> Literal["node_2", "node_3"]:
# Here, let's just do a 50 / 50 split between nodes 2, 3
if random.random() < 0.5:
# 50% of the time, we return Node 2
return "node_2"
# 50% of the time, we return Node 3
return "node_3"
# Build graph
builder = StateGraph(TypedDictState)
builder.add_node("node_1", node_1)
builder.add_node("node_2", node_2)
builder.add_node("node_3", node_3)
# Logic
builder.add_edge(START, "node_1")
builder.add_conditional_edges("node_1", decide_mood)
builder.add_edge("node_2", END)
builder.add_edge("node_3", END)
# Add
graph = builder.compile()
# View
display(Image(graph.get_graph().draw_mermaid_png()))
graph.invoke({"name":"Lance"})
-
在 Python 中,
TypedDict主要用于类型提示(type hints),它确实不会在运行时强制类型检查。这是 Python 的类型系统设计决定的。 -
为什么
TypedDictState不强制:-
Python 的类型提示系统主要是为了帮助开发者编写更安全的代码
-
它不会在运行时强制类型检查,这是为了保持 Python 的动态特性
-
类型检查通常只在开发时通过类型检查器(如 mypy)来执行
-
-
最佳实践建议:
-
虽然类型系统不会强制,但建议遵循
TypedDictState的定义 -
每个节点应该返回完整的
TypedDictState所需的所有字段 -
可以使用类型检查器来确保代码符合类型定义
-
Dataclass
Python 的Dataclass提供了另一种定义结构化数据的方式。Dataclass提供了一种简洁的语法来创建主要用于存储数据的类。
考虑一下这个常规类:
class Exercise:
def __init__(self, name, reps, sets, weight):
self.name = name
self.reps = reps
self.sets = sets
self.weight = weight
那个类定义效率很低——在 __init__ 方法中,每个参数至少重复了三次。相比之下,看看上述代码的Dataclass替代方案:
from dataclasses import dataclass
@dataclass
class Exercise:
name: str
reps: int
sets: int
weight: float # Weight in lbs
某些方法会在数据类中自动生成。小小的 @dataclass 装饰器在幕后实现了 __init__ 、 __repr__ 、 __eq__ 类,这要是手动编写至少得花 20 行代码。
ex1 = Exercise("Bench press", 10, 3, 52.5)
# Verifying Exercise is a regular class
ex1.name
'Bench press'
目前, Exercise 已经实现了 __repr__ 和 __eq__ 方法。让我们来验证一下:
repr(ex1)
#"Exercise(name='Bench press', reps=10, sets=3, weight=52.5)"
ex1 = Exercise("Bench press", 10, 3, 52.5)
ex2 = Exercise("Bench press", 10, 3, 52.5)
ex1 == ex2
#True
ex1 == ex1
#True
数据类允许字段具有默认值,使用 field 函数,该函数可让您对每个字段定义进行更多控制:
from dataclasses import field
@dataclass
class Exercise:
name: str = field(default="Push-up")
reps: int = field(default=10)
sets: int = field(default=3)
weight: float = field(default=0)
# Now, all fields have defaults
ex5 = Exercise()
ex5
Exercise(name='Push-up', reps=10, sets=3, weight=0)
更多关于Dataclass,参见https://www.datacamp.com/tutorial/python-data-classes
接下来,回到第一部分代码中,使用Dataclass替代TypedDict定义State
module2/Dataclass.py
from dataclasses import dataclassfrom
@dataclass
class DataclassState:
name: str
mood: Literal["happy","sad"]
def node_1(state):
print("---Node 1---")
return {"name": state.name + " is ... "}
- 要获取Dataclass的键值,我们只需修改 node_1 中使用的下标操作即可:对于数据类 state,我们使用 state.name 而不是 state[“name”] 来处理上述的 TypedDict
- 您会注意到有一点不太正常:在每个节点中,我们仍然返回一个字典来进行状态更新。这是可行的,因为 LangGraph 会将您状态对象中的每个键分别进行存储。该节点返回的对象只需具备与状态中相同的键(属性)即可!
- 在这种情况下,由于Dataclass具有键名,所以我们可以通过从我们的节点传递一个字典来对其进行更新,就像我们在状态是一个 TypedDict 时所做的那样。
# Build graph
builder = StateGraph(DataclassState)
builder.add_node("node_1", node_1)
builder.add_node("node_2", node_2)
builder.add_node("node_3", node_3)
# Logic
builder.add_edge(START, "node_1")
builder.add_conditional_edges("node_1", decide_mood)
builder.add_edge("node_2", END)
builder.add_edge("node_3", END)
# Add
graph = builder.compile()
# View
display(Image(graph.get_graph().draw_mermaid_png()))
graph.invoke(DataclassState(name="Lance",mood="sad"))
Pydantic
如前所述,TypedDict 和 dataclasses 提供了类型提示,但它们在运行时并不会强制执行类型检查。这意味着您有可能会赋值给无效的变量而不会引发错误!例如,即便我们的类型提示指定了 mood: list[Literal["happy","sad"]],我们也可以将 mood 设定为 mad 。
dataclass_instance = DataclassState(name="Lance", mood="mad")
- Pydantic 是一个使用 Python 类型注解的数据验证和设置管理库。
- 由于其具备验证功能,它特别适合用于在 LangGraph 中定义状态模式。
- Pydantic 能够在运行时执行验证,以检查数据是否符合指定的类型和约束条件。
from pydantic import BaseModel, field_validator, ValidationError
class PydanticState(BaseModel):
name: str
mood: str # "happy" or "sad"
@field_validator('mood')
@classmethod
def validate_mood(cls, value):
# Ensure the mood is either "happy" or "sad"
if value not in ["happy", "sad"]:
raise ValueError("Each mood must be either 'happy' or 'sad'")
return value
try:
state = PydanticState(name="John Doe", mood="mad")
except ValidationError as e:
print("Validation Error:", e)
Validation Error: 1 validation error for PydanticState
mood
Input should be 'happy' or 'sad' [type=literal_error, input_value='mad', input_type=str]
For further information visit https://errors.pydantic.dev/2.8/v/literal_error
我们可以在我们的图中无缝地使用 PydanticState 。
Module2/Pydantic.py
# Build graph
builder = StateGraph(PydanticState)
builder.add_node("node_1", node_1)
builder.add_node("node_2", node_2)
builder.add_node("node_3", node_3)
# Logic
builder.add_edge(START, "node_1")
builder.add_conditional_edges("node_1", decide_mood)
builder.add_edge("node_2", END)
builder.add_edge("node_3", END)
# Add
graph = builder.compile()
# View
display(Image(graph.get_graph().draw_mermaid_png()))
graph.invoke(PydanticState(name="Lance",mood="sad"))
State Reducers
归并函数(reducers)是理解节点(nodes)的更新是如何应用到状态(State)的关键。状态(State)中的每个键(key)都有其自己的独立归并函数。如果没有明确指定归并函数,那么就假设对该键的所有更新都会覆盖它。有几种不同类型的归并函数,从默认类型的归并函数开始。
默认覆盖状态
使用TypedDict定义状态模式,LangGraph默认会覆盖状态值。例如,当输入{‘foo’: 1},经过节点更新后返回{‘foo’: 2}。
from typing_extensions import TypedDict
from IPython.display import Image, display
from langgraph.graph import StateGraph, START, END
class State(TypedDict):
foo: int
def node_1(state):
print("---Node 1---")
return {"foo": state['foo'] + 1}
# Build graph
builder = StateGraph(State)
builder.add_node("node_1", node_1)
# Logic
builder.add_edge(START, "node_1")
builder.add_edge("node_1", END)
# Add
graph = builder.compile()
# View
display(Image(graph.get_graph().draw_mermaid_png()))
graph.invoke({"foo" : 1})
---Node 1---
{'foo': 2}
分支导致的更新冲突
当节点分支导致多个节点在同一步骤中更新状态时,LangGraph会报错,因为它不知道应该保留哪个更新。
class State(TypedDict):
foo: int
def node_1(state):
print("---Node 1---")
return {"foo": state['foo'] + 1}
def node_2(state):
print("---Node 2---")
return {"foo": state['foo'] + 1}
def node_3(state):
print("---Node 3---")
return {"foo": state['foo'] + 1}
# Build graph
builder = StateGraph(State)
builder.add_node("node_1", node_1)
builder.add_node("node_2", node_2)
builder.add_node("node_3", node_3)
# Logic
builder.add_edge(START, "node_1")
builder.add_edge("node_1", "node_2")
builder.add_edge("node_1", "node_3")
builder.add_edge("node_2", END)
builder.add_edge("node_3", END)
# Add
graph = builder.compile()
# View
display(Image(graph.get_graph().draw_mermaid_png()))
from langgraph.errors import InvalidUpdateError
try:
graph.invoke({"foo" : 1})
except InvalidUpdateError as e:
print(f"InvalidUpdateError occurred: {e}")
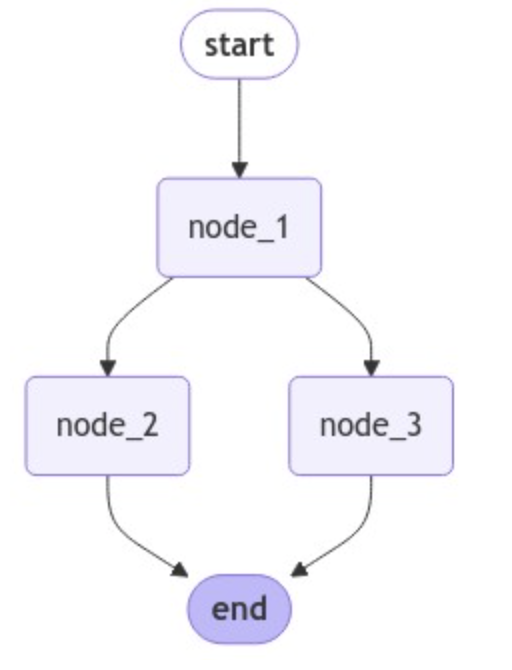
---Node 1---
---Node 2---
---Node 3---
InvalidUpdateError occurred: At key 'foo': Can receive only one value per step. Use an Annotated key to handle multiple values.
使用Reducer解决更新冲突
使用Annotated类型指定Reducer函数,如operator.add,可以将更新追加到列表中,而不是覆盖它们。
module2/reducer.py
from operator import add
from typing import Annotated
class State(TypedDict):
foo: Annotated[list[int], add]
def node_1(state):
print("---Node 1---")
return {"foo": [state['foo'][0] + 1]}
# Build graph
builder = StateGraph(State)
builder.add_node("node_1", node_1)
# Logic
builder.add_edge(START, "node_1")
builder.add_edge("node_1", END)
# Add
graph = builder.compile()
# View
display(Image(graph.get_graph().draw_mermaid_png()))
graph.invoke({"foo" : [1]})
---Node 1---
{'foo': [1, 2]}
现在,我们的“foo”这个状态键是一个列表。这个 operator.add 加法器函数(add是LangGraph内置函数)会将每个节点的更新内容添加到这个列表中。
def node_1(state):
print("---Node 1---")
return {"foo": [state['foo'][-1] + 1]}
def node_2(state):
print("---Node 2---")
return {"foo": [state['foo'][-1] + 1]}
def node_3(state):
print("---Node 3---")
return {"foo": [state['foo'][-1] + 1]}
# Build graph
builder = StateGraph(State)
builder.add_node("node_1", node_1)
builder.add_node("node_2", node_2)
builder.add_node("node_3", node_3)
# Logic
builder.add_edge(START, "node_1")
builder.add_edge("node_1", "node_2")
builder.add_edge("node_1", "node_3")
builder.add_edge("node_2", END)
builder.add_edge("node_3", END)
# Add
graph = builder.compile()
# View
display(Image(graph.get_graph().draw_mermaid_png()))
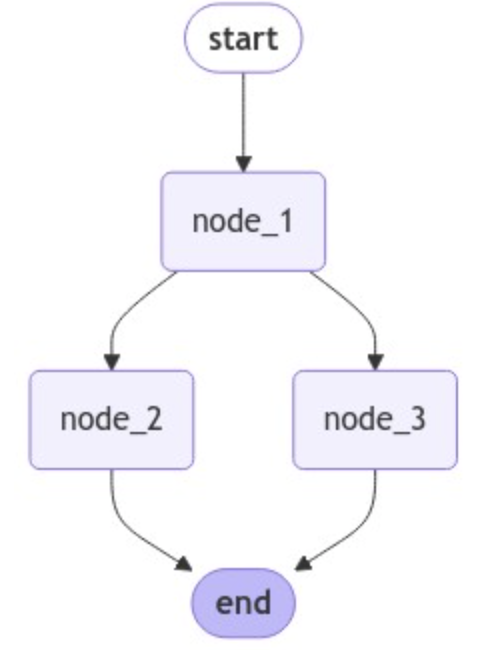
我们可以看到,节点 2 和节点 3 的更新是并行执行的,因为它们处于同一步骤中。
---Node 1---
---Node 2---
---Node 3---
{'foo': [1, 2, 3, 3]}
state['foo'][-1] 的含义是:
state是一个字典(dict),它有一个键'foo'。state['foo']取出字典中键为'foo'的值。- 由于
state['foo']是一个列表(list),比如[1, 2, 3]。state['foo'][-1]表示取这个列表的最后一个元素。 - 在 Python 中,索引
-1代表列表的最后一个元素。
举例说明:
state = {'foo': [10, 20, 30]}
last_value = state['foo'][-1] # 结果是 30
在代码中,state['foo'][-1] + 1 就是把 foo 列表最后一个元素加 1。
现在,让我们看看如果将 None 传递给 foo 函数会发生什么情况。我们发现了一个错误,因为我们的归约器(operator.add)在node_1 中尝试将作为输入传入的 None 类型对象连接起来形成列表。
try:
graph.invoke({"foo" : None})
except TypeError as e:
print(f"TypeError occurred: {e}")
TypeError occurred: can only concatenate list (not "NoneType") to list
Custom Reducers
我们可以自定义Reducer,例如:让我们定义自定义的reducer逻辑来组合列表,并处理其中一个或两个输入可能为None的情况。
def reduce_list(left: list | None, right: list | None) -> list:
"""Safely combine two lists, handling cases where either or both inputs might be None.
Args:
left (list | None): The first list to combine, or None.
right (list | None): The second list to combine, or None.
Returns:
list: A new list containing all elements from both input lists.
If an input is None, it's treated as an empty list.
"""
if not left:
left = []
if not right:
right = []
return left + right
class DefaultState(TypedDict):
foo: Annotated[list[int], add]
class CustomReducerState(TypedDict):
foo: Annotated[list[int], reduce_list]
Messages
-
在模块 1 中,我们展示了如何使用内置的归约函数 add_messages 来处理状态中的消息。
-
如果您想要处理消息,那么 MessagesState 就是一个非常有用的快捷方式。
-
MessagesState 具有内置的消息键
-
它还为这个键具有一个内置的消息添加器(add_messages)函数
-
-
为了简洁起见,我们将通过从
from langgraph.graph import MessagesState模块导入 MessagesState 类的方式来使用它。
from typing import Annotated
from langgraph.graph import MessagesState
from langchain_core.messages import AnyMessage
from langgraph.graph.message import add_messages
# Define a custom TypedDict that includes a list of messages with add_messages reducer
class CustomMessagesState(TypedDict):
messages: Annotated[list[AnyMessage], add_messages]
added_key_1: str
added_key_2: str
# etc
# Use MessagesState, which includes the messages key with add_messages reducer
class ExtendedMessagesState(MessagesState):
# Add any keys needed beyond messages, which is pre-built
added_key_1: str
added_key_2: str
# etc
from langgraph.graph.message import add_messages
from langchain_core.messages import AIMessage, HumanMessage
# Initial state
initial_messages = [AIMessage(content="Hello! How can I assist you?", name="Model"),
HumanMessage(content="I'm looking for information on marine biology.", name="Lance")
]
# New message to add
new_message = AIMessage(content="Sure, I can help with that. What specifically are you interested in?", name="Model")
# Test
add_messages(initial_messages , new_message)
输出
[AIMessage(content='Hello! How can I assist you?', name='Model', id='f470d868-cf1b-45b2-ae16-48154cd55c12'),
HumanMessage(content="I'm looking for information on marine biology.", name='Lance', id='a07a88c5-cb2a-4cbd-9485-5edb9d658366'),
AIMessage(content='Sure, I can help with that. What specifically are you interested in?', name='Model', id='7938e615-86c2-4cbb-944b-c9b2342dee68')]
重写
让我们展示一下在使用 add_messages reducer时的一些实用技巧。 如果我们向我们的消息列表中发送一条具有与现有消息相同 ID 的信息,那么这条信息将会被覆盖掉!
# Initial state
initial_messages = [AIMessage(content="Hello! How can I assist you?", name="Model", id="1"),
HumanMessage(content="I'm looking for information on marine biology.", name="Lance", id="2")
]
# New message to add
new_message = HumanMessage(content="I'm looking for information on whales, specifically", name="Lance", id="2")
# Test
add_messages(initial_messages , new_message)
[AIMessage(content='Hello! How can I assist you?', name='Model', id='1'),
HumanMessage(content="I'm looking for information on whales, specifically", name='Lance', id='2')]
移除
“add_messages” 还支持消息删除功能。为此,我们只需使用 langchain_core 中的 RemoveMessage 函数即可。
from langchain_core.messages import RemoveMessage
# Message list
messages = [AIMessage("Hi.", name="Bot", id="1")]
messages.append(HumanMessage("Hi.", name="Lance", id="2"))
messages.append(AIMessage("So you said you were researching ocean mammals?", name="Bot", id="3"))
messages.append(HumanMessage("Yes, I know about whales. But what others should I learn about?", name="Lance", id="4"))
# Isolate messages to delete
delete_messages = [RemoveMessage(id=m.id) for m in messages[:-2]]
print(delete_messages)
[RemoveMessage(content='', id='1'), RemoveMessage(content='', id='2')]
/var/folders/l9/bpjxdmfx7lvd1fbdjn38y5dh0000gn/T/ipykernel_17703/3097054180.py:10: LangChainBetaWarning: The class `RemoveMessage` is in beta. It is actively being worked on, so the API may change.
delete_messages = [RemoveMessage(id=m.id) for m in messages[:-2]]
add_messages(messages , delete_messages)
[AIMessage(content='So you said you were researching ocean mammals?', name='Bot', id='3'),
HumanMessage(content='Yes, I know about whales. But what others should I learn about?', name='Lance', id='4')]
我们可以看到,正如在删除消息操作中所指出的那样,消息 ID 1 和 2 已由归约器删除。稍后我们会看到这一点付诸实践的情况。
Multiple Schemas
-
更多控制权:在默认情况下,所有图节点通常都采用单一数据结构(State Schema),这个单一模式包含图的输入和输出键/通道。然而,有些时候这种单一模式的通信方式并不能满足所有的需求,我们希望能够对这种通信模式进行更精细的控制,以适应更复杂的场景。
-
内部节点传递非必需信息:在图的内部,节点之间可能需要传递一些信息,这些信息对于整个图的输入和输出来说并不是必要的。也就是说,这些信息只是在图的内部节点之间进行交互和处理,不需要在图的外部接口中暴露出来。例如,在一个数据处理流程的图中,内部节点可能需要传递一些中间状态信息或者调试信息,这些信息对于最终的输入和输出结果来说并不重要,但它们对于内部节点之间的协作和数据处理过程是有帮助的。
-
使用不同的输入/输出模式:除了内部节点传递非必需信息的情况,我们还可能希望为整个图使用不同的输入和输出模式。这意味着图的输入和输出可以有多种不同的结构和形式,而不是固定为一种单一的模式。例如,图的输出可能只需要包含一个特定的关键输出键,而不是像默认情况下那样包含所有可能的输出键。这种灵活性可以让我们根据不同的需求和场景来定制图的行为和接口,使得图能够更好地适应各种复杂的应用场景。
私有状态的传递
from typing_extensions import TypedDict
from IPython.display import Image, display
from langgraph.graph import StateGraph, START, END
class OverallState(TypedDict):
foo: int
class PrivateState(TypedDict):
baz: int
def node_1(state: OverallState) -> PrivateState:
print("---Node 1---")
return {"baz": state['foo'] + 1}
def node_2(state: PrivateState) -> OverallState:
print("---Node 2---")
return {"foo": state['baz'] + 1}
# Build graph
builder = StateGraph(OverallState)
builder.add_node("node_1", node_1)
builder.add_node("node_2", node_2)
# Logic
builder.add_edge(START, "node_1")
builder.add_edge("node_1", "node_2")
builder.add_edge("node_2", END)
# Add
graph = builder.compile()
graph.invoke({"foo" : 1})
通过定义 OverallState 和 PrivateState,节点 node_1 使用 OverallState 作为输入,输出为 PrivateState,而节点 node_2 使用 PrivateState 作为输入,输出为 OverallState。这种设计使得某些中间状态(如 baz)不会出现在图的最终输出中。
{'foo': 3}
输入/输出模式的定义
module2/multischema.py
from IPython.display import Image, display
from langgraph.graph import StateGraph, START, END
from typing_extensions import TypedDict
class InputState(TypedDict):
question: str
class OutputState(TypedDict):
answer: str
class OverallState(TypedDict):
question: str
answer: str
notes: str
def thinking_node(state: InputState):
return {"answer": "bye", "notes": "... his is name is Lance"}
def answer_node(state: OverallState) -> OutputState:
return {"answer": "bye Lance"}
graph = StateGraph(OverallState, input=InputState, output=OutputState)
graph.add_node("answer_node", answer_node)
graph.add_node("thinking_node", thinking_node)
graph.add_edge(START, "thinking_node")
graph.add_edge("thinking_node", "answer_node")
graph.add_edge("answer_node", END)
graph = graph.compile()
# View
#display(Image(graph.get_graph().draw_mermaid_png()))
messages = graph.invoke({"question":"hi"})
print(messages)
通过定义 InputState 和 OutputState,并使用这些模式来约束图的输入和输出。关键代码是:
graph = StateGraph(OverallState, input=InputState, output=OutputState)
我们为图设定一个特定的输入与输出模式,输入/输出模式会对图的输入和输出中允许使用的键进行筛选。
此外,我们可以使用一个类型提示state: InputState来指定我们每个节点的输入模式,例如:def thinking_node(state: InputState):当图采用多种数据模型时,这一点就显得尤为重要。
我们在下面使用类型提示def answer_node(state: OverallState) -> OutputState:,表明 answer_node 的输出将会被过滤为 OutputState 。
{'answer': 'bye Lance'}
过滤和修剪消息
接下来讨论ChatBot类应用中的MessagesState。
- 消息过滤 介绍如何通过过滤消息来减少传递给模型的消息数量,以应对长对话导致的高令牌使用和延迟问题。展示了如何删除除最近两条消息之外的所有消息。
from langchain_core.messages import RemoveMessage
# Nodes
def filter_messages(state: MessagesState):
# Delete all but the 2 most recent messages
delete_messages = [RemoveMessage(id=m.id) for m in state["messages"][:-2]]
return {"messages": delete_messages}
def chat_model_node(state: MessagesState):
return {"messages": [llm.invoke(state["messages"])]}
# Build graph
builder = StateGraph(MessagesState)
builder.add_node("filter", filter_messages)
builder.add_node("chat_model", chat_model_node)
builder.add_edge(START, "filter")
builder.add_edge("filter", "chat_model")
builder.add_edge("chat_model", END)
graph = builder.compile()
# View
display(Image(graph.get_graph().draw_mermaid_png()))
如果您不需要或不想修改图形状态,那么您只需过滤您传递给聊天模型的消息即可。
例如,只需将一个经过筛选的列表传入模型中:llm.invoke(messages[-1:]) 。
# Node
def chat_model_node(state: MessagesState):
return {"messages": [llm.invoke(state["messages"][-1:])]}
# Build graph
builder = StateGraph(MessagesState)
builder.add_node("chat_model", chat_model_node)
builder.add_edge(START, "chat_model")
builder.add_edge("chat_model", END)
graph = builder.compile()
# View
display(Image(graph.get_graph().draw_mermaid_png()))
- 消息修剪 介绍了另一种优化方法,即根据指定的令牌数量修剪消息。与过滤不同,修剪限制了聊天模型可以使用的令牌数量,展示了如何实现基于令牌数量的消息修剪。
from langchain_core.messages import trim_messages
# Node
def chat_model_node(state: MessagesState):
messages = trim_messages(
state["messages"],
max_tokens=100,
strategy="last",
token_counter=ChatOpenAI(model="gpt-4o"),
allow_partial=False,
)
return {"messages": [llm.invoke(messages)]}
# Build graph
builder = StateGraph(MessagesState)
builder.add_node("chat_model", chat_model_node)
builder.add_edge(START, "chat_model")
builder.add_edge("chat_model", END)
graph = builder.compile()
# View
display(Image(graph.get_graph().draw_mermaid_png()))
具备消息摘要功能的聊天机器人
传统的对话处理方式通常是通过修剪或过滤消息来减少信息量,但这种方式会导致部分信息丢失。为了更好地保留完整对话的核心内容,我们将展示如何利用大型语言模型(LLMs)来生成对话的实时摘要。这种摘要能够以一种压缩的形式呈现整个对话的关键信息,而不是像修剪或过滤那样直接移除某些内容。
我们将把这种对话摘要功能整合到一个简单的聊天机器人中。并且,为了让聊天机器人能够支持长时间的对话,同时避免产生高昂的令牌成本或延迟,我们会为其配备记忆功能。
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o",temperature=0)
from langgraph.graph import MessagesState
class State(MessagesState):
summary: str
我们将像之前那样使用 MessagesState 。除了内置的消息键之外,我们现在还将添加一个自定义键(摘要)。
我们将定义一个节点,用于调用包含摘要(如果有的话)的我们的语言模型(LLM)。
from langchain_core.messages import SystemMessage, HumanMessage, RemoveMessage
# Define the logic to call the model
def call_model(state: State):
# Get summary if it exists
summary = state.get("summary", "")
# If there is summary, then we add it
if summary:
# Add summary to system message
system_message = f"Summary of conversation earlier: {summary}"
# Append summary to any newer messages
messages = [SystemMessage(content=system_message)] + state["messages"]
else:
messages = state["messages"]
response = model.invoke(messages)
return {"messages": response}
我们将定义一个节点来生成摘要。 注意,在我们生成摘要之后,这里我们将使用 RemoveMessage 来过滤我们的状态数据。
def summarize_conversation(state: State):
# First, we get any existing summary
summary = state.get("summary", "")
# Create our summarization prompt
if summary:
# A summary already exists
summary_message = (
f"This is summary of the conversation to date: {summary}\n\n"
"Extend the summary by taking into account the new messages above:"
)
else:
summary_message = "Create a summary of the conversation above:"
# Add prompt to our history
messages = state["messages"] + [HumanMessage(content=summary_message)]
response = model.invoke(messages)
# Delete all but the 2 most recent messages
delete_messages = [RemoveMessage(id=m.id) for m in state["messages"][:-2]]
return {"summary": response.content, "messages": delete_messages}
我们将添加一个条件边,以便根据对话的长度来决定是否生成摘要。
from langgraph.graph import END
# Determine whether to end or summarize the conversation
def should_continue(state: State):
"""Return the next node to execute."""
messages = state["messages"]
# If there are more than six messages, then we summarize the conversation
if len(messages) > 6:
return "summarize_conversation"
# Otherwise we can just end
return END
添加内存
- 在图执行的单一过程中,状态是短暂存在的。这种短暂性限制了我们进行带有中断的多轮对话的能力。
- 在模块1的结尾部分,我们介绍了可以利用持久化来解决这一问题。LangGraph能够借助检查点工具(checkpointer)在每一步执行之后自动保存图的状态。
- 这一内嵌的持久化层级赋予了我们“记忆”功能,使得LangGraph能够从最后一次状态更新的地方继续执行。
- 正如我们之前所展示的,MemorySaver是与图状态配合使用的一种相对容易操作的内存键值存储方式。
- 我们只需将图与检查点工具一起编译,那么这个图就具备了“记忆”能力。
from IPython.display import Image, display
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import StateGraph, START
# Define a new graph
workflow = StateGraph(State)
workflow.add_node("conversation", call_model)
workflow.add_node(summarize_conversation)
# Set the entrypoint as conversation
workflow.add_edge(START, "conversation")
workflow.add_conditional_edges("conversation", should_continue)
workflow.add_edge("summarize_conversation", END)
# Compile
memory = MemorySaver()
graph = workflow.compile(checkpointer=memory)
display(Image(graph.get_graph().draw_mermaid_png()))
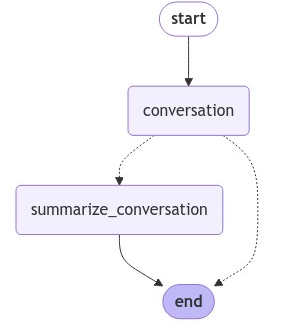
Threads
检查点保存器会在每一步将状态保存为一个检查点。这些已保存的检查点可以被归类为一个对话线程。可以将 Slack 作为类比来理解:不同的频道承载着不同的对话。线程就如同 Slack 的频道,捕捉成组的状态集合(例如对话)。在下面,我们使用可配置的设置来设定一个线程 ID。
# Create a thread
config = {"configurable": {"thread_id": "1"}}
# Start conversation
input_message = HumanMessage(content="hi! I'm Lance")
output = graph.invoke({"messages": [input_message]}, config)
for m in output['messages'][-1:]:
m.pretty_print()
input_message = HumanMessage(content="what's my name?")
output = graph.invoke({"messages": [input_message]}, config)
for m in output['messages'][-1:]:
m.pretty_print()
input_message = HumanMessage(content="i like the 49ers!")
output = graph.invoke({"messages": [input_message]}, config)
for m in output['messages'][-1:]:
m.pretty_print()
目前,我们还没有关于状态的概要信息,因为我们收到的消息数量仍不超过 6 条。
graph.get_state(config).values.get("summary","")
带有线程 ID 的 config 允许我们从之前记录的状态继续进行操作!
input_message = HumanMessage(content="i like Nick Bosa, isn't he the highest paid defensive player?")
output = graph.invoke({"messages": [input_message]}, config)
for m in output['messages'][-1:]:
m.pretty_print()
================================== Ai Message ==================================
Yes, Nick Bosa is indeed one of the highest-paid defensive players in the NFL. In September 2023, he signed a record-breaking contract extension with the San Francisco 49ers, making him the highest-paid defensive player at that time. His performance on the field has certainly earned him that recognition. It's great to hear you're a fan of such a talented player!
继续
graph.get_state(config).values.get("summary","")
"Lance introduced himself and mentioned that he is a fan of the San Francisco 49ers. He specifically likes Nick Bosa and inquired if Bosa is the highest-paid defensive player. I confirmed that Nick Bosa signed a record-breaking contract extension in September 2023, making him the highest-paid defensive player at that time, and acknowledged Bosa's talent and Lance's enthusiasm for the player."
完整代码,见module2/chatbot-summarization.py