LangGraph-4-Building Your Assistant
我们将深入到多智能体工作流程,并建立一个多智能体研究助理,将本课程中的所有模块联系在一起。
为了构建这个多智能体研究助手,我们首先讨论几个LangGraph可控性的主题。
Parallelization
Fan out and fan in
在并行计算或分布式系统中,“Fan out”和“Fan in”通常用于描述数据流的分发和汇总过程:
Fan out(扇出):指的是将一个任务或数据分发到多个并行的处理单元或节点上。例如,在分布式计算中,一个主节点(master node)将一个大型任务分解为多个子任务,并将这些子任务分配给多个从节点(worker nodes)进行并行处理。
Fan in(扇入):指的是将多个并行处理单元或节点的输出结果汇总到一个节点或处理单元上。例如,在分布式计算中,多个从节点完成任务后,将结果发送回主节点,主节点对这些结果进行汇总和整合。
在本节中,Fan out是将一个任务分解为多个子任务并分配给多个节点的过程,以实现并行处理。Fan in是将多个节点的处理结果汇总和合并的过程,以生成最终结果。
from IPython.display import Image, display
from typing import Any
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
class State(TypedDict):
# The operator.add reducer fn makes this append-only
state: str
class ReturnNodeValue:
def __init__(self, node_secret: str):
self._value = node_secret
def __call__(self, state: State) -> Any:
print(f"Adding {self._value} to {state['state']}")
return {"state": [self._value]}
# Add nodes
builder = StateGraph(State)
# Initialize each node with node_secret
builder.add_node("a", ReturnNodeValue("I'm A"))
builder.add_node("b", ReturnNodeValue("I'm B"))
builder.add_node("c", ReturnNodeValue("I'm C"))
builder.add_node("d", ReturnNodeValue("I'm D"))
# Flow
builder.add_edge(START, "a")
builder.add_edge("a", "b")
builder.add_edge("b", "c")
builder.add_edge("c", "d")
builder.add_edge("d", END)
graph = builder.compile()
# import common.render
# common.render.renderGraph(graph)
graph.invoke({"state": []})
ReturnNodeValue类为什么能作为一个node在builder.add_node中添加?这是因为Python的”可调用对象”(callable)机制。
ReturnNodeValue类实现了__call__方法:
def __call__(self, state: State) -> Any:
print(f"Adding {self._value} to {state['state']}")
return {"state": [self._value]}
在Python中,任何实现了__call__方法的对象都可以像函数一样被调用。这种对象被称为”可调用对象”。
现在,让我们并行运行 b 和 c,然后运行 d 。我们可以轻松地从 a 分叉到 b 和 c,然后再合并到 d。状态更新在每一步的末尾进行应用。
builder = StateGraph(State)
# Initialize each node with node_secret
builder.add_node("a", ReturnNodeValue("I'm A"))
builder.add_node("b", ReturnNodeValue("I'm B"))
builder.add_node("c", ReturnNodeValue("I'm C"))
builder.add_node("d", ReturnNodeValue("I'm D"))
# Flow
builder.add_edge(START, "a")
builder.add_edge("a", "b")
builder.add_edge("a", "c")
builder.add_edge("b", "d")
builder.add_edge("c", "d")
builder.add_edge("d", END)
graph = builder.compile()
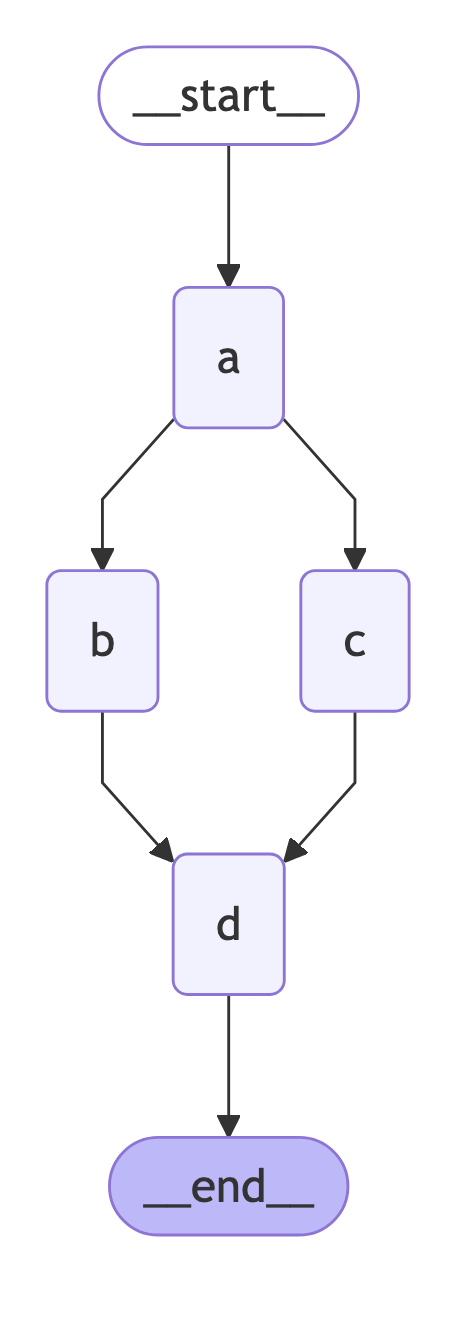
我们发现了一个错误!这是因为 b 和 c 在同一步骤中都对同一个状态键/通道进行了写入操作。
from langgraph.errors import InvalidUpdateError
try:
graph.invoke({"state": []})
except InvalidUpdateError as e:
print(f"An error occurred: {e}")
Adding I'm A to []
Adding I'm B to ["I'm A"]
Adding I'm C to ["I'm A"]
An error occurred: At key 'state': Can receive only one value per step. Use an Annotated key to handle multiple values.
For troubleshooting, visit: https://python.langchain.com/docs/troubleshooting/errors/INVALID_CONCURRENT_GRAPH_UPDATE
- 使用负载输出出时,如果步骤写入相同的通道/键,我们需要确保使用了reducer。
- 正如我们在模块 2 中提到的,add 是内置的 operator 模块中的一个函数。
- 当将 add 应用于列表时,它会执行列表连接操作。
替换State,添加reducer
#class State(TypedDict):
# # The operator.add reducer fn makes this append-only
# state: str
#
import operator
from typing import Annotated
class State(TypedDict):
# The operator.add reducer fn makes this append-only
state: Annotated[list, operator.add]
修改后执行graph.invoke({"state": []})
Adding I'm A to []
Adding I'm B to ["I'm A"]
Adding I'm C to ["I'm A"]
Adding I'm D to ["I'm A", "I'm B", "I'm C"]
现在我们可以看到,我们将b和c并行进行的更新添加到state中。
完整代码module4/parallelization-1.py
from IPython.display import Image, display
from typing import Any
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
import operator
from typing import Annotated
class State(TypedDict):
# The operator.add reducer fn makes this append-only
state: Annotated[list, operator.add]
class ReturnNodeValue:
def __init__(self, node_secret: str):
self._value = node_secret
def __call__(self, state: State) -> Any:
print(f"Adding {self._value} to {state['state']}")
return {"state": [self._value]}
builder = StateGraph(State)
# Initialize each node with node_secret
builder.add_node("a", ReturnNodeValue("I'm A"))
builder.add_node("b", ReturnNodeValue("I'm B"))
builder.add_node("c", ReturnNodeValue("I'm C"))
builder.add_node("d", ReturnNodeValue("I'm D"))
# Flow
builder.add_edge(START, "a")
builder.add_edge("a", "b")
builder.add_edge("a", "c")
builder.add_edge("b", "d")
builder.add_edge("c", "d")
builder.add_edge("d", END)
graph = builder.compile()
import common.render
common.render.renderGraph(graph)
#graph.invoke({"state": []})
from langgraph.errors import InvalidUpdateError
try:
graph.invoke({"state": []})
except InvalidUpdateError as e:
print(f"An error occurred: {e}")
等待node完成
现在,让我们考虑一种情况,其中一条并行路径的步骤比另一条多。
builder = StateGraph(State)
# Initialize each node with node_secret
builder.add_node("a", ReturnNodeValue("I'm A"))
builder.add_node("b", ReturnNodeValue("I'm B"))
builder.add_node("b2", ReturnNodeValue("I'm B2"))
builder.add_node("c", ReturnNodeValue("I'm C"))
builder.add_node("d", ReturnNodeValue("I'm D"))
# Flow
builder.add_edge(START, "a")
builder.add_edge("a", "b")
builder.add_edge("a", "c")
builder.add_edge("b", "b2")
builder.add_edge(["b2", "c"], "d")
builder.add_edge("d", END)
graph = builder.compile()
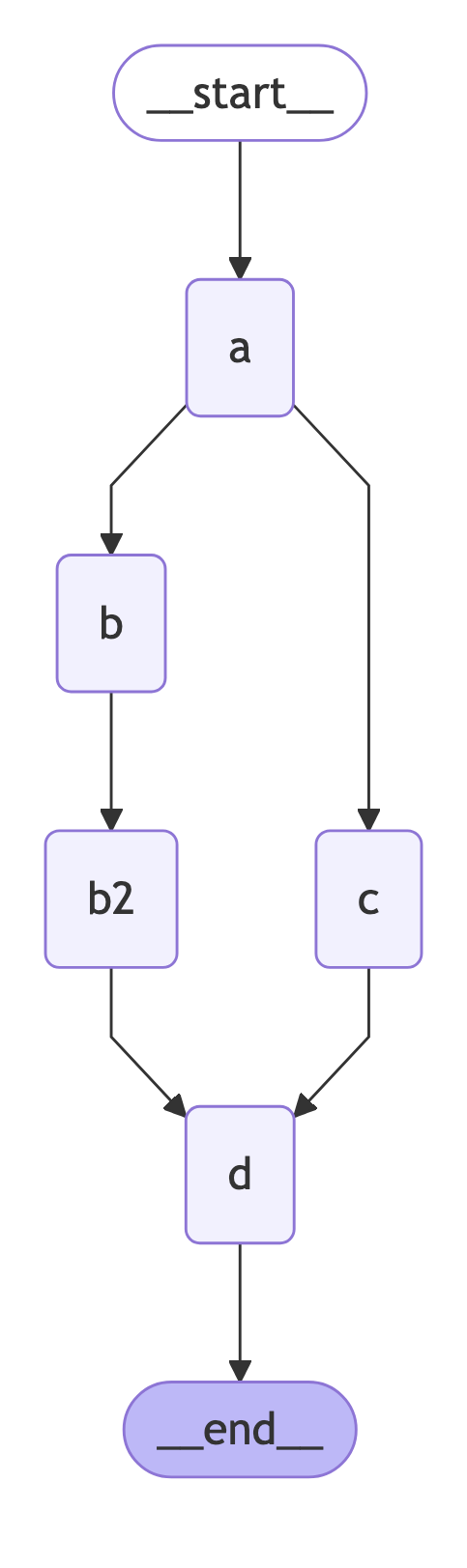
在这种情况下,b、b2和c都是同一步骤的一部分。图将等待所有这些操作完成后再进入步骤d。
执行graph.invoke({"state": []})
Adding I'm A to []
Adding I'm B to ["I'm A"]
Adding I'm C to ["I'm A"]
Adding I'm B2 to ["I'm A", "I'm B", "I'm C"]
Adding I'm D to ["I'm A", "I'm B", "I'm C", "I'm B2"]
设置状态更新顺序
在状态更新的过程中,虽然我们无法直接控制每一步中状态更新的具体顺序(因为这个顺序是由LangGraph根据图的拓扑结构确定的),但是我们可以通过使用自定义的reducer来对状态更新的顺序进行定制,比如按照某种规则对状态更新进行排序。
具体来说,我们看到c被添加到b2之前。但是,我们可以使用自定义reducer来定制,对状态更新进行排序。
def sorting_reducer(left, right):
""" Combines and sorts the values in a list"""
if not isinstance(left, list):
left = [left]
##isinstance() 是 Python 的一个内置函数,用于检查一个对象是否属于某个特定的类型。
if not isinstance(right, list):
right = [right]
return sorted(left + right, reverse=False)
class State(TypedDict):
# sorting_reducer will sort the values in state
state: Annotated[list, sorting_reducer]
# Add nodes
builder = StateGraph(State)
# Initialize each node with node_secret
builder.add_node("a", ReturnNodeValue("I'm A"))
builder.add_node("b", ReturnNodeValue("I'm B"))
builder.add_node("b2", ReturnNodeValue("I'm B2"))
builder.add_node("c", ReturnNodeValue("I'm C"))
builder.add_node("d", ReturnNodeValue("I'm D"))
# Flow
builder.add_edge(START, "a")
builder.add_edge("a", "b")
builder.add_edge("a", "c")
builder.add_edge("b", "b2")
builder.add_edge(["b2", "c"], "d")
builder.add_edge("d", END)
graph = builder.compile()
输出
Adding I'm A to []
Adding I'm B to ["I'm A"]
Adding I'm C to ["I'm A"]
Adding I'm B2 to ["I'm A", "I'm B", "I'm C"]
Adding I'm D to ["I'm A", "I'm B", "I'm B2", "I'm C"]
现在,reducer会对更新后的状态值进行排序!
sorting_reducer的例子对所有值进行全局排序。我们还可以:
- 在并行步骤中将输出写入状态中的单独字段
- 在并行步骤之后使用“sink”节点来组合和排序这些输出
- 合并后清空临时字段
与LLM结合
现在,让我们添加一个现实的例子!我们想从两个外部来源(维基百科和web - search)收集上下文,并让LLM回答一个问题。
module4/parallelization-2.py
import sys
import os
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
# 设置Tavily API密钥
os.environ["TAVILY_API_KEY"] = "" # 请替换为您的实际API密钥
from IPython.display import Image, display
from typing import Any
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
import operator
from typing import Annotated
import common.customModel
llm = common.customModel.customModel()
class State(TypedDict):
question: str
answer: str
context: Annotated[list, operator.add]
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_community.document_loaders import WikipediaLoader
from langchain_community.tools import TavilySearchResults
def search_web(state):
""" Retrieve docs from web search """
# Search
tavily_search = TavilySearchResults(max_results=3)
search_docs = tavily_search.invoke(state['question'])
# Format
formatted_search_docs = "\n\n---\n\n".join(
[
f'<Document href="{doc["url"]}">\n{doc["content"]}\n</Document>'
for doc in search_docs
]
)
return {"context": [formatted_search_docs]}
def search_wikipedia(state):
""" Retrieve docs from wikipedia """
# Search
search_docs = WikipediaLoader(query=state['question'],
load_max_docs=2).load()
# Format
formatted_search_docs = "\n\n---\n\n".join(
[
f'<Document source="{doc.metadata["source"]}" page="{doc.metadata.get("page", "")}">\n{doc.page_content}\n</Document>'
for doc in search_docs
]
)
return {"context": [formatted_search_docs]}
def generate_answer(state):
""" Node to answer a question """
# Get state
context = state["context"]
question = state["question"]
# Template
answer_template = """Answer the question {question} using this context: {context}"""
answer_instructions = answer_template.format(question=question,
context=context)
# Answer
answer = llm.invoke([SystemMessage(content=answer_instructions)]+[HumanMessage(content=f"Answer the question.")])
# Append it to state
return {"answer": answer}
# Add nodes
builder = StateGraph(State)
# Initialize each node with node_secret
builder.add_node("search_web",search_web)
builder.add_node("search_wikipedia", search_wikipedia)
builder.add_node("generate_answer", generate_answer)
# Flow
builder.add_edge(START, "search_wikipedia")
builder.add_edge(START, "search_web")
builder.add_edge("search_wikipedia", "generate_answer")
builder.add_edge("search_web", "generate_answer")
builder.add_edge("generate_answer", END)
graph = builder.compile()
# import common.render
# common.render.renderGraph(graph)
from langgraph.errors import InvalidUpdateError
try:
result = graph.invoke({"question": "How were Nvidia's Q2 2024 earnings"})
print(result['answer'].content)
except InvalidUpdateError as e:
print(f"An error occurred: {e}")
##需要在终端设置代理
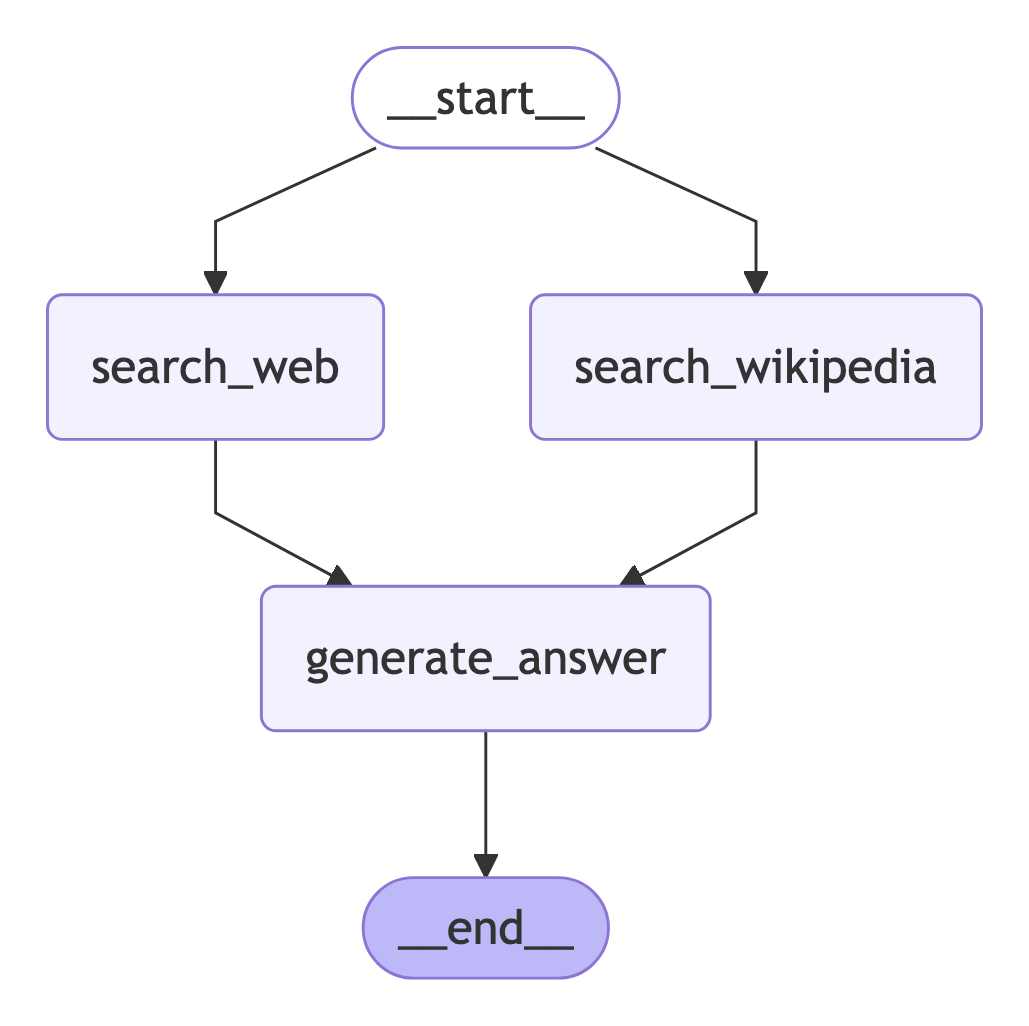
输出
NVIDIA reported strong financial results for the second quarter of fiscal 2025 (Q2 2024). Here are the key highlights:
- **Revenue**: NVIDIA's revenue for Q2 2024 was $30.0 billion, up 15% from the previous quarter and up 122% from the same period a year ago.
- **Earnings per Share (EPS)**:
- **GAAP EPS**: $0.67, up 12% from the previous quarter and up 168% from a year ago.
- **Non-GAAP EPS**: $0.68, up 11% from the previous quarter and up 152% from a year ago.
- **Data Center Division**: The data center division had record revenue of $26.3 billion, up 16% sequentially and up 150.4% year-over-year, driven by strong demand for NVIDIA Hopper GPU computing and networking platforms.
- **Shareholder Returns**: During the first half of fiscal 2025, NVIDIA returned $15.4 billion to shareholders through share repurchases and cash dividends. As of the end of Q2, the company had $7.5 billion remaining under its share repurchase authorization. Additionally, on August 26, 2024, the Board of Directors approved an additional $50.0 billion in share repurchase authorization, without expiration.
Overall, NVIDIA's Q2 2024 earnings were very strong, with significant growth in both revenue and earnings, driven by robust performance in the data center segment.
sub-graph
子图允许你在图的不同部分创建和管理不同的状态。这对于多智能体系统特别有用,因为多智能体系统由一组智能体组成,每个智能体都有自己的状态。
当添加子图时,你需要定义父图和子图之间的通信方式:
- Shared state schemas(共享状态模式)——父图和子图在其状态模式中具有共享状态键
- Different state schemas(不同的状态模式)——在父图和子图模式中没有共享的状态键
Shared State Schemas(共享状态模式)
- 定义:父图和子图(子图即子图)共享某些状态键(state keys),这些键在父图和子图的 schema 中是相同的。
- 实现方式:
- 父图和子图直接通过共享的状态键进行通信。
- 子图可以直接访问和修改父图的状态,而无需额外的转换逻辑。
- 优点:
- 简单直接,适合简单的父子图关系,尤其是当父子图之间有紧密的逻辑联系时。
- 减少了转换逻辑的复杂性,因为不需要在父图和子图之间进行状态的映射。
- 缺点:
- 父图和子图的状态高度耦合,灵活性较差。如果需要修改状态键的名称或结构,可能需要同时修改父图和子图的代码。
- 不适合复杂的系统,尤其是当父图和子图的逻辑差异较大时。
Different State Schemas(不同状态模式)
- 定义:父图和子图的状态键完全不同,没有共享的状态键。
- 实现方式:
- 需要定义一个节点函数(node function),该函数负责将父图的状态转换为子图的状态,并在子图执行完成后,将子图的输出转换回父图的状态。
- 这种方式通过转换逻辑实现了父子图之间的解耦。
- 优点:
- 父图和子图的状态完全独立,灵活性更高。父图和子图可以独立修改状态键的名称或结构,而不会影响对方。
- 更适合复杂的系统,尤其是当父图和子图的逻辑差异较大时。
- 缺点:
- 实现复杂度较高,需要编写额外的转换逻辑。
- 性能可能略低于共享状态模式,因为需要进行状态的转换。
本质区别
虽然两种方式都通过 schema 传递信息,但它们的核心区别在于 耦合程度 和 灵活性:
- 共享状态模式 是一种 紧耦合 的方式,父图和子图的状态高度依赖,适合简单的父子图关系。
- 不同状态模式 是一种 松耦合 的方式,父图和子图的状态完全独立,适合复杂的系统,尤其是当父子图的逻辑差异较大时。
示例
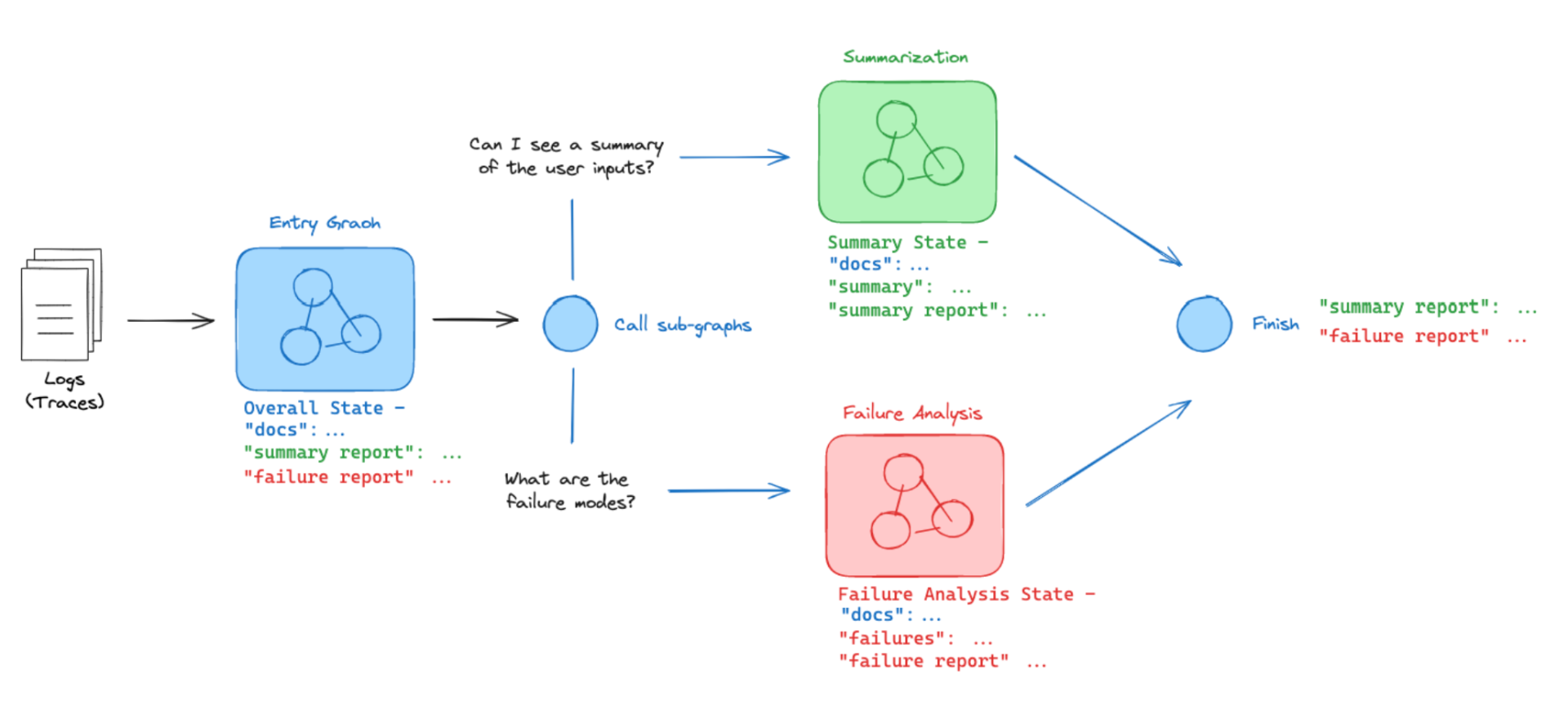
让我们考虑一个简单的例子:
- 我有一个接受日志的系统
- 它由不同的代理执行两个独立的子任务(汇总日志,查找故障模式)
- 我想在两个不同的子图上执行这两个操作。
最关键的是要理解图是如何通信的!图之间的通信是通过重叠的键(over-lapping keys)来实现的。
- 子图访问父图文档:子图可以访问父图中的文档(docs)。这意味着子图可以获取父图中存储的原始数据或其他共享信息,作为自己处理任务的输入。
- 父图访问子图结果:父图可以访问子图生成的总结(summary)和故障报告(failure_report)。这样,父图可以根据子图的处理结果进行进一步的操作或决策,实现整个系统的协同工作。
定义日志Log
让我们为将输入到图中的日志定义一个模式。
from operator import add
from typing_extensions import TypedDict
from typing import List, Optional, Annotated
# The structure of the logs
class Log(TypedDict):
id: str
question: str
docs: Optional[List]
answer: str
grade: Optional[int]
grader: Optional[str]
feedback: Optional[str]
子图Sub graphs
第一个:失败分析子图,它使用FailureAnalysisState。
from IPython.display import Image, display
from langgraph.graph import StateGraph, START, END
# Failure Analysis Sub-graph
class FailureAnalysisState(TypedDict):
cleaned_logs: List[Log]
failures: List[Log]
fa_summary: str
processed_logs: List[str]
class FailureAnalysisOutputState(TypedDict):
fa_summary: str
processed_logs: List[str]
def get_failures(state):
""" Get logs that contain a failure """
cleaned_logs = state["cleaned_logs"]
failures = [log for log in cleaned_logs if "grade" in log]
return {"failures": failures}
def generate_summary(state):
""" Generate summary of failures """
failures = state["failures"]
# Add fxn: fa_summary = summarize(failures)
fa_summary = "Poor quality retrieval of Chroma documentation."
return {"fa_summary": fa_summary, "processed_logs": [f"failure-analysis-on-log-{failure['id']}" for failure in failures]}
fa_builder = StateGraph(FailureAnalysisState,output=FailureAnalysisOutputState)
fa_builder.add_node("get_failures", get_failures)
fa_builder.add_node("generate_summary", generate_summary)
fa_builder.add_edge(START, "get_failures")
fa_builder.add_edge("get_failures", "generate_summary")
fa_builder.add_edge("generate_summary", END)
graph = fa_builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))
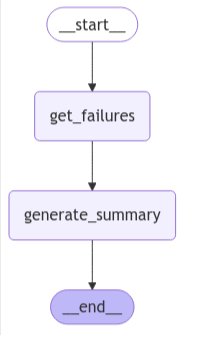
fa_builder = StateGraph(FailureAnalysisState,output=FailureAnalysisOutputState) 通过StateGraph参数指定了,输入State与输出State不同。
第二个:问题摘要子图,它使用QuestionSummarizationState。
# Summarization subgraph
class QuestionSummarizationState(TypedDict):
cleaned_logs: List[Log]
qs_summary: str
report: str
processed_logs: List[str]
class QuestionSummarizationOutputState(TypedDict):
report: str
processed_logs: List[str]
def generate_summary(state):
cleaned_logs = state["cleaned_logs"]
# Add fxn: summary = summarize(generate_summary)
summary = "Questions focused on usage of ChatOllama and Chroma vector store."
return {"qs_summary": summary, "processed_logs": [f"summary-on-log-{log['id']}" for log in cleaned_logs]}
def send_to_slack(state):
qs_summary = state["qs_summary"]
# Add fxn: report = report_generation(qs_summary)
report = "foo bar baz"
return {"report": report}
qs_builder = StateGraph(QuestionSummarizationState,output=QuestionSummarizationOutputState)
qs_builder.add_node("generate_summary", generate_summary)
qs_builder.add_node("send_to_slack", send_to_slack)
qs_builder.add_edge(START, "generate_summary")
qs_builder.add_edge("generate_summary", "send_to_slack")
qs_builder.add_edge("send_to_slack", END)
graph = qs_builder.compile()
display(Image(graph.get_graph().draw_mermaid_png()))
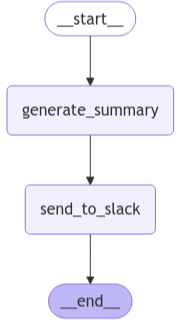
添加子图到父图
现在,我们可以把它们放在一起。我们使用EntryGraphState创建父图。我们将子图添加为节点!
entry_builder.add_node("question_summarization", qs_builder.compile())
entry_builder.add_node("failure_analysis", fa_builder.compile())
# Entry Graph
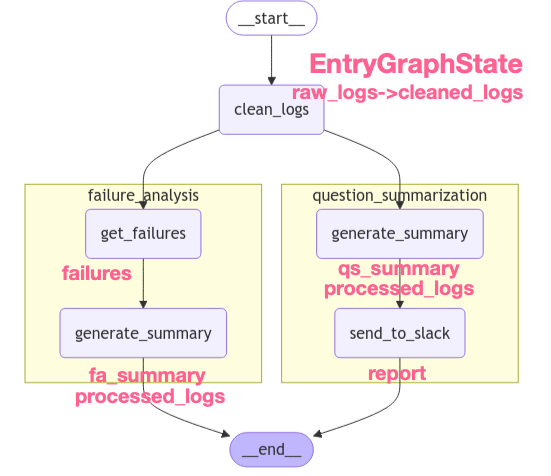
class EntryGraphState(TypedDict):
raw_logs: List[Log]
cleaned_logs: Annotated[List[Log], add] # This will be USED BY in BOTH sub-graphs
fa_summary: str # This will only be generated in the FA sub-graph
report: str # This will only be generated in the QS sub-graph
processed_logs: Annotated[List[int], add] # This will be generated in BOTH sub-graphs
这里提出了一个疑问,如果cleaned_logs只进入每个子图作为输入,为什么还要有一个reducer呢?它没有被修改。也就是说,按常理来说,如果一个数据只是作为输入,没有被修改或处理,那么通常不需要归并器来处理它。
这是因为子图的输出状态将包含所有的键,即使它们没有被修改。子图是并行运行的。因为并行子图返回相同的键,所以需要一个类似reducer的操作符。Add以组合来自每个子图的传入值。
但是,我们可以通过之前讨论过的另一个概念来解决这个问题。我们可以为每个子图创建一个输出状态模式(schema),并确保这个输出状态模式包含不同的键来作为输出。实际上,我们并不需要每个子图都输出cleaned_logs。通过这种方式,可以避免并行子图返回相同键的问题,从而也就不需要归并器来处理cleaned_logs了。
# Entry Graph
class EntryGraphState(TypedDict):
raw_logs: List[Log]
cleaned_logs: List[Log]
fa_summary: str # This will only be generated in the FA sub-graph
report: str # This will only be generated in the QS sub-graph
processed_logs: Annotated[List[int], add] # This will be generated in BOTH sub-graphs
def clean_logs(state):
# Get logs
raw_logs = state["raw_logs"]
# Data cleaning raw_logs -> docs
cleaned_logs = raw_logs
return {"cleaned_logs": cleaned_logs}
entry_builder = StateGraph(EntryGraphState)
entry_builder.add_node("clean_logs", clean_logs)
entry_builder.add_node("question_summarization", qs_builder.compile())
entry_builder.add_node("failure_analysis", fa_builder.compile())
entry_builder.add_edge(START, "clean_logs")
entry_builder.add_edge("clean_logs", "failure_analysis")
entry_builder.add_edge("clean_logs", "question_summarization")
entry_builder.add_edge("failure_analysis", END)
entry_builder.add_edge("question_summarization", END)
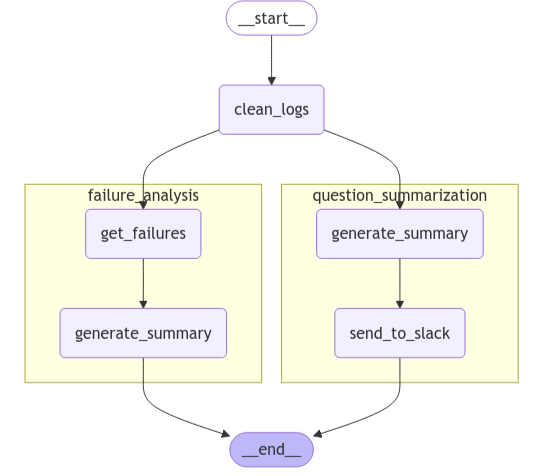
graph = entry_builder.compile()
from IPython.display import Image, display
# Setting xray to 1 will show the internal structure of the nested graph
display(Image(graph.get_graph(xray=1).draw_mermaid_png()))
为了清楚的标记各个node输出字段,增加一张标注了各个node子段修改的图
然后构造一些Log对象,拼接成数组,作为raw_logs参数传入图
# Dummy logs
question_answer = Log(
id="1",
question="How can I import ChatOllama?",
answer="To import ChatOllama, use: 'from langchain_community.chat_models import ChatOllama.'",
)
question_answer_feedback = Log(
id="2",
question="How can I use Chroma vector store?",
answer="To use Chroma, define: rag_chain = create_retrieval_chain(retriever, question_answer_chain).",
grade=0,
grader="Document Relevance Recall",
feedback="The retrieved documents discuss vector stores in general, but not Chroma specifically",
)
raw_logs = [question_answer,question_answer_feedback]
graph.invoke({"raw_logs": raw_logs})
输出
{'raw_logs': [{'id': '1', 'question': 'How can I import ChatOllama?', 'answer': "To import ChatOllama, use: 'from langchain_community.chat_models import ChatOllama.'"}, {'id': '2', 'question': 'How can I use Chroma vector store?', 'answer': 'To use Chroma, define: rag_chain = create_retrieval_chain(retriever, question_answer_chain).', 'grade': 0, 'grader': 'Document Relevance Recall', 'feedback': 'The retrieved documents discuss vector stores in general, but not Chroma specifically'}],
'cleaned_logs': [{'id': '1', 'question': 'How can I import ChatOllama?', 'answer': "To import ChatOllama, use: 'from langchain_community.chat_models import ChatOllama.'"}, {'id': '2', 'question': 'How can I use Chroma vector store?', 'answer': 'To use Chroma, define: rag_chain = create_retrieval_chain(retriever, question_answer_chain).', 'grade': 0, 'grader': 'Document Relevance Recall', 'feedback': 'The retrieved documents discuss vector stores in general, but not Chroma specifically'}],
'fa_summary': 'Poor quality retrieval of Chroma documentation.',
'report': 'foo bar baz', 'processed_logs': ['failure-analysis-on-log-2', 'summary-on-log-1', 'summary-on-log-2']}
map-reduce
背景介绍
- 默认情况:在LangGraph中,默认情况下,节点(Nodes)和边(Edges)是提前定义好的,并且它们都是基于同一个共享状态进行操作的。这种设计适用于很多场景,因为这样可以让各个节点之间能够方便地共享和更新状态信息。
- 特殊需求:然而,在某些情况下,这种默认的设计方式会存在局限性。具体来说,可能存在以下两种情况:
- 边的不确定性:在某些场景下,我们可能无法提前确定具体的边。也就是说,我们无法事先知道节点之间的连接关系会是怎样的。这可能是因为某些节点的输出会动态地影响后续节点的执行路径,从而导致边的连接关系需要在运行时才能确定。
- 状态的多样性:我们可能希望在同一个图中同时存在不同版本的状态。例如,在处理一些复杂的业务逻辑时,不同的节点可能需要基于不同的状态来进行操作,而不是共享同一个状态。这就需要有一种机制能够支持在图中同时存在多个状态版本,并且能够根据需要将这些状态传递给不同的节点。
-
map-reduce简介:map-reduce是一种常见的分布式计算设计模式,它主要分为两个阶段:map阶段和reduce阶段。在map阶段,会将输入的数据分割成多个小的数据块,然后对每个数据块分别进行处理,生成中间结果;在reduce阶段,会将map阶段生成的中间结果进行汇总和合并,最终得到最终的结果。
- Send对象的引入:为了支持这种map-reduce设计模式,LangGraph提供了一种解决方案,即支持从条件边(conditional edges)返回Send对象。
- Send对象的定义:Send对象包含两个参数。第一个参数是目标节点的名称,它指定了要将状态传递给哪个下游节点;第二个参数是要传递给该节点的状态。
- 工作原理:通过这种方式,当第一个节点生成了对象列表后,就可以为列表中的每个对象创建一个Send对象。每个Send对象都指定了一个下游节点,并且携带了针对该对象的独立状态。然后,LangGraph会根据这些Send对象,将不同的状态传递给不同的下游节点,从而实现了在运行时动态地确定边的连接关系以及为不同的节点提供不同的状态版本,很好地解决了map-reduce模式下的问题。
总之,LangGraph如何通过引入Send对象来支持map-reduce设计模式,从而解决了在该模式下边的不确定性和状态多样性的问题,使得LangGraph能够更加灵活地应对各种复杂的业务场景和计算模式。
生成笑话示例
让我们设计一个系统来做两件事:
-
(1)Map——创建一组关于某个主题的笑话。
-
(2)Reduce——从列表中选出最好的笑话。
我们将使用LLM来进行工作生成和选择。
from langchain_openai import ChatOpenAI
# Prompts we will use
subjects_prompt = """Generate a list of 3 sub-topics that are all related to this overall topic: {topic}."""
joke_prompt = """Generate a joke about {subject}"""
best_joke_prompt = """Below are a bunch of jokes about {topic}. Select the best one! Return the ID of the best one, starting 0 as the ID for the first joke. Jokes: \n\n {jokes}"""
# LLM
model = ChatOpenAI(model="gpt-4o", temperature=0)
笑话并行化生成
首先,让我们定义图的入口点:
- 用户输入主题topic
- 根据topic生成一个笑话话题列表subjects
- 将每个笑话主题发送到我们上面的笑话生成节点
我们的状态有一个jokes键,它会累积并行化笑话生成的笑话
import operator
from typing import Annotated
from typing_extensions import TypedDict
from pydantic import BaseModel
class Subjects(BaseModel):
subjects: list[str] # 笑话话题列表subjects,由LLM生成
class BestJoke(BaseModel):
id: int
class OverallState(TypedDict):
topic: str #用户输入的主题
subjects: list
jokes: Annotated[list, operator.add] # 设置了reducer,处理合并
best_selected_joke: str
创造笑话的主题。
def generate_topics(state: OverallState):
prompt = subjects_prompt.format(topic=state["topic"])
response = model.with_structured_output(Subjects).invoke(prompt)
return {"subjects": response.subjects}
神奇之处在于:我们使用Send为每个主题创造一个笑话。
这非常有用!它可以自动并行生成任意数量的笑话。
generate_joke: the name of the node in the graph{"subject": s}: the state to send
Send允许你传递任何你想要的状态到generate_joke。它不必与OverallState保持一致。
from langgraph.constants import Send
def continue_to_jokes(state: OverallState):
return [Send("generate_joke", {"subject": s}) for s in state["subjects"]]
continue_to_jokes函数,接收一个 OverallState 类型的参数,return返回值中,
-
使用列表推导式遍历 state[“subjects”] 中的所有子主题
-
对每个子主题 s,创建一个 Send 操作
-
Send 操作指定了下一个要执行的动作是 “generate_joke”
-
每个 Send 操作都携带了当前子主题作为参数
笑话生成(Map)
现在,我们只需要定义一个创建笑话的节点generate_joke!我们把他们写回OverallState中的jokes,这个key有一个用于合并列表的reducer。
class JokeState(TypedDict):
subject: str
class Joke(BaseModel):
joke: str
def generate_joke(state: JokeState):
prompt = joke_prompt.format(subject=state["subject"])
response = model.with_structured_output(Joke).invoke(prompt)
return {"jokes": [response.joke]}
最佳笑话选择(reduce)
添加逻辑选择最佳笑话
def best_joke(state: OverallState):
jokes = "\n\n".join(state["jokes"])
prompt = best_joke_prompt.format(topic=state["topic"], jokes=jokes)
response = model.with_structured_output(BestJoke).invoke(prompt)
return {"best_selected_joke": state["jokes"][response.id]}
这个函数是 Map-Reduce 模式中的 “Reduce” 部分,用于从所有生成的笑话中选择最佳的一个
- 将 state[“jokes”] 列表中的所有笑话用换行符连接成一个字符串,这样做的目的是为了格式化所有笑话,使其在提示词中更易读
- 使用 best_joke_prompt 模板,将主题和所有笑话插入到提示词中
- 使用 with_structured_output(BestJoke) 确保输出符合 BestJoke 模型的结构,BestJoke 模型只包含一个 id 字段,表示最佳笑话的索引
- 根据模型返回的 id 从原始笑话列表中选择对应的笑话,将选中的最佳笑话作为 best_selected_joke 返回
这个函数的工作流程是:收集所有生成的笑话让 AI 模型评估所有笑话选择最佳的一个笑话返回选中的笑话这是 Map-Reduce 模式中的 “Reduce” 阶段,它将之前并行生成的所有笑话(Map 阶段的结果)整合起来,通过 AI 模型的选择,最终确定一个最佳笑话。
编译
from IPython.display import Image
from langgraph.graph import END, StateGraph, START
# Construct the graph: here we put everything together to construct our graph
graph = StateGraph(OverallState)
graph.add_node("generate_topics", generate_topics)
graph.add_node("generate_joke", generate_joke)
graph.add_node("best_joke", best_joke)
graph.add_edge(START, "generate_topics")
graph.add_conditional_edges("generate_topics", continue_to_jokes, ["generate_joke"])
graph.add_edge("generate_joke", "best_joke")
graph.add_edge("best_joke", END)
# Compile the graph
app = graph.compile()
Image(app.get_graph().draw_mermaid_png())
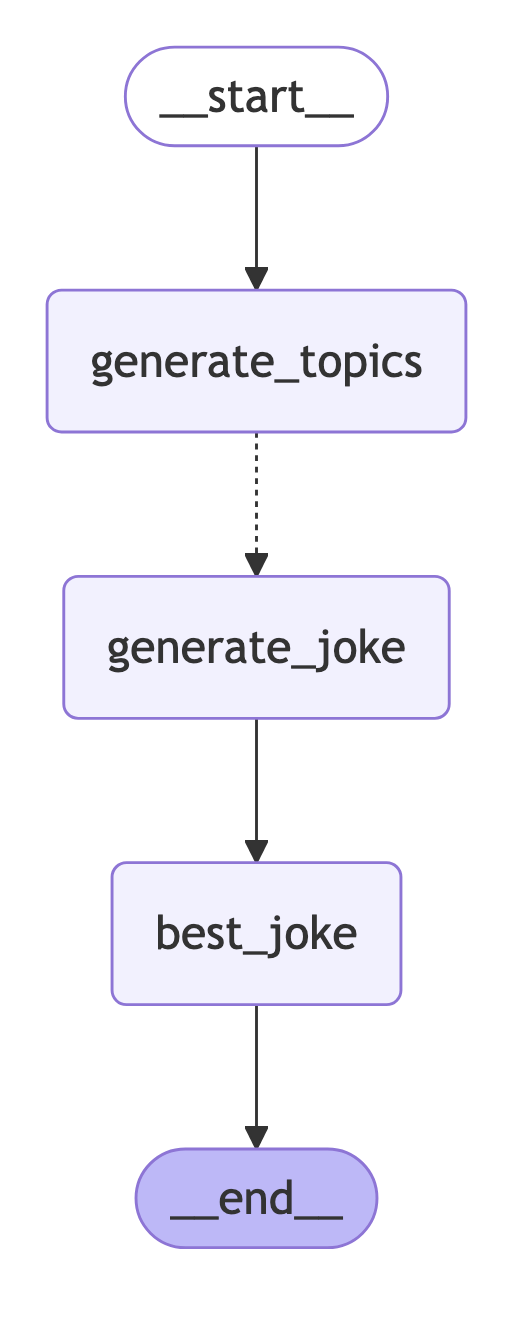
add_conditional_edges 是 LangGraph 框架中用于添加条件边(conditional edges)的方法,它用于定义工作流中的动态路由。让我们详细分析这行代码:
graph.add_conditional_edges("generate_topics", continue_to_jokes, ["generate_joke"])
这个函数调用包含三个主要参数:
- 第一个参数 “generate_topics”:表示边的起始节点,这是生成子主题的节点
- 第二个参数 continue_to_jokes:这是一个条件函数,它决定了下一步应该执行什么操作;在这个例子中,它会返回一个列表,包含多个 Send 操作,每个 Send 操作都指向 “generate_joke” 节点。
- 第三个参数 [“generate_joke”]:这是一个目标节点列表,表示条件函数可能返回的所有可能的目标节点,在这个例子中,只有一个可能的目标节点
工作流程:
- 当 generate_topics 节点执行完成后
- 系统会调用 continue_to_jokes 函数
- continue_to_jokes 函数会为每个子主题创建一个 Send 操作
- 每个 Send 操作都会触发 generate_joke 节点
- 这样实现了并行处理多个子主题
这种设计允许:
-
动态路由:根据当前状态决定下一步操作
-
并行处理:可以同时处理多个子任务
-
灵活的工作流:可以根据需要创建多个分支
这是 Map-Reduce 模式中实现并行处理的关键部分,它使得系统能够同时为多个子主题生成笑话,而不是按顺序处理。
补充说明add_conditional_edges 函数
add_conditional_edges(
source: str,
path: Union[
Callable[..., Union[Hashable, list[Hashable]]],
Callable[
..., Awaitable[Union[Hashable, list[Hashable]]]
],
Runnable[Any, Union[Hashable, list[Hashable]]],
],
path_map: Optional[
Union[dict[Hashable, str], list[str]]
] = None,
then: Optional[str] = None,
) -> Self
https://langchain-ai.github.io/langgraph/reference/graphs/?h=add_conditional_edges#langgraph.graph.state.StateGraph.add_edge
让我详细解释一下 add_conditional_edges 函数的参数:
source: str- 这是边的起始节点名称
- 必须是一个字符串
- 表示从哪个节点开始进行条件路由
- 例如:
"generate_topics"
path: Union[Callable[..., Union[Hashable, list[Hashable]]], Callable[..., Awaitable[Union[Hashable, list[Hashable]]]], Runnable[Any, Union[Hashable, list[Hashable]]]]- 这是一个条件函数,用于决定下一步路由
- 可以是三种类型之一: a. 普通函数:返回一个可哈希值或可哈希值列表 b. 异步函数:返回一个可哈希值或可哈希值列表的异步结果 c. Runnable 对象:可以执行并返回可哈希值或可哈希值列表
- 例如:
continue_to_jokes函数返回一个Send操作列表
path_map: Optional[Union[dict[Hashable, str], list[str]]] = None- 可选参数,默认值为 None
- 可以是两种类型: a. 字典:将条件函数的返回值映射到目标节点名称 b. 字符串列表:直接指定可能的目标节点
- 例如:
["generate_joke"]
then: Optional[str] = None- 可选参数,默认值为 None
- 指定条件路由完成后的下一个节点
- 如果提供,所有条件分支完成后都会转到这个节点
- 返回值:
Self- 返回图对象本身
- 支持链式调用
使用示例:
# 基本用法
graph.add_conditional_edges(
source="generate_topics",
path=continue_to_jokes,
path_map=["generate_joke"]
)
# 使用字典映射
graph.add_conditional_edges(
source="node_a",
path=condition_function,
path_map={"result1": "node_b", "result2": "node_c"}
)
# 使用 then 参数
graph.add_conditional_edges(
source="node_a",
path=condition_function,
path_map=["node_b", "node_c"],
then="node_d"
)
这个函数的设计允许:
- 灵活的路由逻辑:可以根据不同条件选择不同的路径
- 并行处理:可以同时触发多个目标节点
- 异步支持:可以使用异步函数进行条件判断
- 链式调用:可以连续添加多个条件边
这是 LangGraph 框架中实现复杂工作流的关键组件,特别适合实现 Map-Reduce 这样的并行处理模式。
执行图
# Call the graph: here we call it to generate a list of jokes
for s in app.stream({"topic": "animals"}):
print(s)
输出
{'generate_topics': {'subjects': ['Animal Behavior and Communication', 'Conservation and Biodiversity', 'Evolution and Adaptation of Animals']}}
{'generate_joke': {'jokes': ["Why did the conservationist break up with biodiversity? Because it was too spread out, and he couldn't keep track of all the species!"]}}
{'generate_joke': {'jokes': ['Why did the dog sit in front of the computer all day? He was trying to learn how to bark in different fonts!']}}
{'generate_joke': {'jokes': ['Why did the chameleon start carrying a diary? Because it wanted to keep track of all its changes, in case it adapted too quickly and forgot who it was yesterday!']}}
{'best_joke': {'best_selected_joke': 'Why did the chameleon start carrying a diary? Because it wanted to keep track of all its changes, in case it adapted too quickly and forgot who it was yesterday!'}}
注意:由于需要json格式输出,调整model参数和prompt
model = ChatOpenAI(
api_key="your key",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
model="qwen-max",
model_kwargs={
"response_format": {"type": "json_object"} ##json
}
)
完整代码module4/map-reduce.py(调整了prompt)
import sys
import os
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
import operator
from typing import Annotated
from typing_extensions import TypedDict
from pydantic import BaseModel
class Subjects(BaseModel):
subjects: list[str]
class BestJoke(BaseModel):
id: int
class OverallState(TypedDict):
topic: str
subjects: list
jokes: Annotated[list, operator.add]
best_selected_joke: str
# Prompts we will use
subjects_prompt = """Generate a list of 3 sub-topics that are all related to this overall topic: {topic}.
Please return the response in JSON format with a 'subjects' array containing the sub-topics."""
joke_prompt = """Generate a joke about {subject}.
Please return the response in JSON format with a 'joke' field containing the joke text."""
best_joke_prompt = """Below are a bunch of jokes about {topic}. Select the best one!
Please return the response in JSON format with an 'id' field containing the index of the best joke (starting from 0).
Jokes: \n\n {jokes}"""
import common.customModel
model = common.customModel.modelResJson()
def generate_topics(state: OverallState):
prompt = subjects_prompt.format(topic=state["topic"])
response = model.with_structured_output(Subjects).invoke(prompt)
return {"subjects": response.subjects}
from langgraph.constants import Send
def continue_to_jokes(state: OverallState):
return [Send("generate_joke", {"subject": s}) for s in state["subjects"]]
# Joke generation (map)
class JokeState(TypedDict):
subject: str
class Joke(BaseModel):
joke: str
def generate_joke(state: JokeState):
prompt = joke_prompt.format(subject=state["subject"])
response = model.with_structured_output(Joke).invoke(prompt)
return {"jokes": [response.joke]}
#Best joke selection (reduce)
def best_joke(state: OverallState):
jokes = "\n\n".join(state["jokes"])
prompt = best_joke_prompt.format(topic=state["topic"], jokes=jokes)
response = model.with_structured_output(BestJoke).invoke(prompt)
return {"best_selected_joke": state["jokes"][response.id]}
from IPython.display import Image
from langgraph.graph import END, StateGraph, START
# Construct the graph: here we put everything together to construct our graph
graph = StateGraph(OverallState)
graph.add_node("generate_topics", generate_topics)
graph.add_node("generate_joke", generate_joke)
graph.add_node("best_joke", best_joke)
graph.add_edge(START, "generate_topics")
graph.add_conditional_edges("generate_topics", continue_to_jokes, ["generate_joke"])
graph.add_edge("generate_joke", "best_joke")
graph.add_edge("best_joke", END)
# Compile the graph
app = graph.compile()
# import common.render
# common.render.renderGraph(app)
# Call the graph: here we call it to generate a list of jokes
for s in app.stream({"topic": "animals"}):
print(s)