LangGraph-5-Long-Term Memory
记忆是一种认知功能,它允许人们存储、检索,并利用信息来了解他们的现在和未来。
Short vs Long-term memory
短期与长期记忆
短期记忆
短期记忆可以让应用程序记住单个线程或会话中的之前交互。线程在会话中组织多个交互,类似于电子邮件在单个会话中分组消息的方式。
LangGraph管理短期记忆,将其作为代理状态的一部分,通过线程作用域检查点进行持久化。该状态通常包括对话历史记录以及其他有状态的数据,例如上传的文件、检索的文档或生成的工件。通过将这些存储在图的状态中,机器人可以访问给定对话的完整上下文,同时保持不同线程之间的分离。
长期记忆
长期记忆是在会话线程之间共享的。它可以在任何时间,在任何线程中被召回。内存的作用域可以是任何自定义的命名空间,而不仅仅是一个线程ID。LangGraph提供了store来让你保存和回忆长期记忆。
对比
| Short-term | Long-term | |
|---|---|---|
| Scope | Within session(thread) | Across session(thread) |
| Example use-case | Persist conversational history, allow interruptions in a chat (e.g., if user is idle or to allow human-in-the-loop) | Remember information about a specific user across all chat sessions |
| LangGraph usage | Checkpointer | Store |
人类长期记忆
- Episodic memory(情节记忆):情节记忆主要涉及个人亲身经历的特定事件和情景,这些经历通常与时间、地点和相关的情感有关。例如,您记得昨天去海边度假的具体细节,包括看到的风景、感受到的微风等。
- Semantic memory(语义记忆):语义记忆则是关于一般性的知识、概念、事实和语言信息等,不依赖于个人的具体经历或特定时间和地点。比如,您知道巴黎是法国的首都,数学中的定理,或者各种语言的词汇和语法规则等。
- procedural memory(程序性记忆):一种长期的潜意识记忆,用于执行特定类型的动作。
Agent长期记忆
对应人类的三种一致
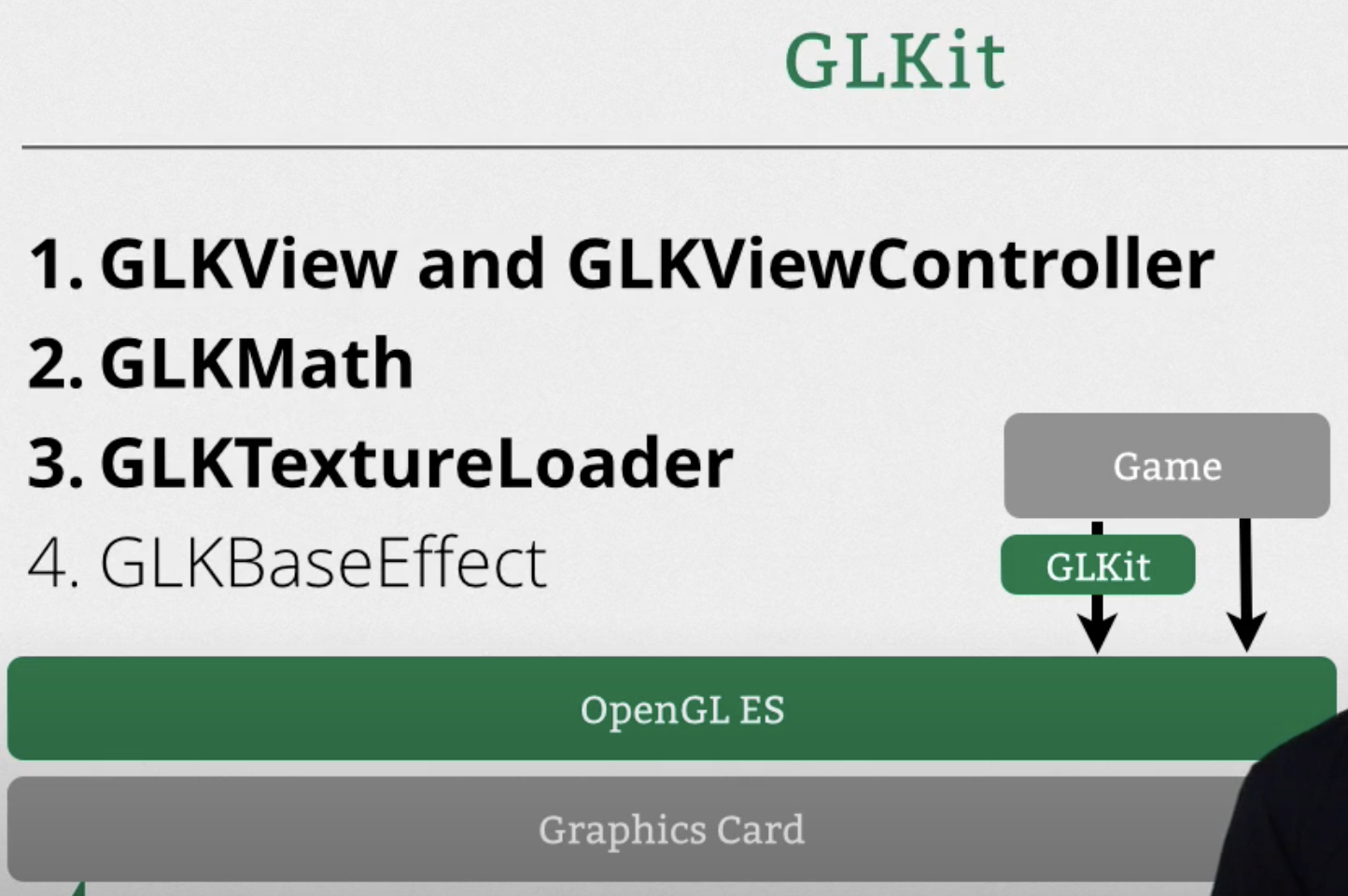
- Episodic memory(情节记忆):agent过去的动作
- Semantic memory(语义记忆):用户个人的具体经历或特定时间和地点
- procedural memory(程序性记忆):Agent的提示词prompt
Chatbot with Memory
这里,我们将介绍一种保存和检索长时记忆的方法——LangGraph内存存储。
我们将构建一个同时使用短期(线程内)和长期(跨线程)内存的聊天机器人。
我们将关注长期语义记忆,这将是关于用户的事实。
这些长期记忆将被用于创建一个个性化的聊天机器人,它可以记住有关用户的事实。
它将在“热路径”中节省内存,因为用户正在与它聊天。热路径是指在程序运行过程中被频繁调用或执行的部分。在AI代理中,这通常是指代理在与用户交互或处理实时任务时直接涉及的逻辑。
虽然人类经常在睡眠期间形成长期记忆,但AI智能体需要一种不同的方法。智能体何时以及如何创建新记忆?智能体至少有两种主要的方法来编写记忆:“在热路径上”和“在后台”。
LangGraph Store介绍
LangGraph内存存储提供了一种在LangGraph中跨线程存储和检索信息的方法。
这是一个用于持久键值存储的开源基类。
import uuid
from langgraph.store.memory import InMemoryStore
in_memory_store = InMemoryStore()
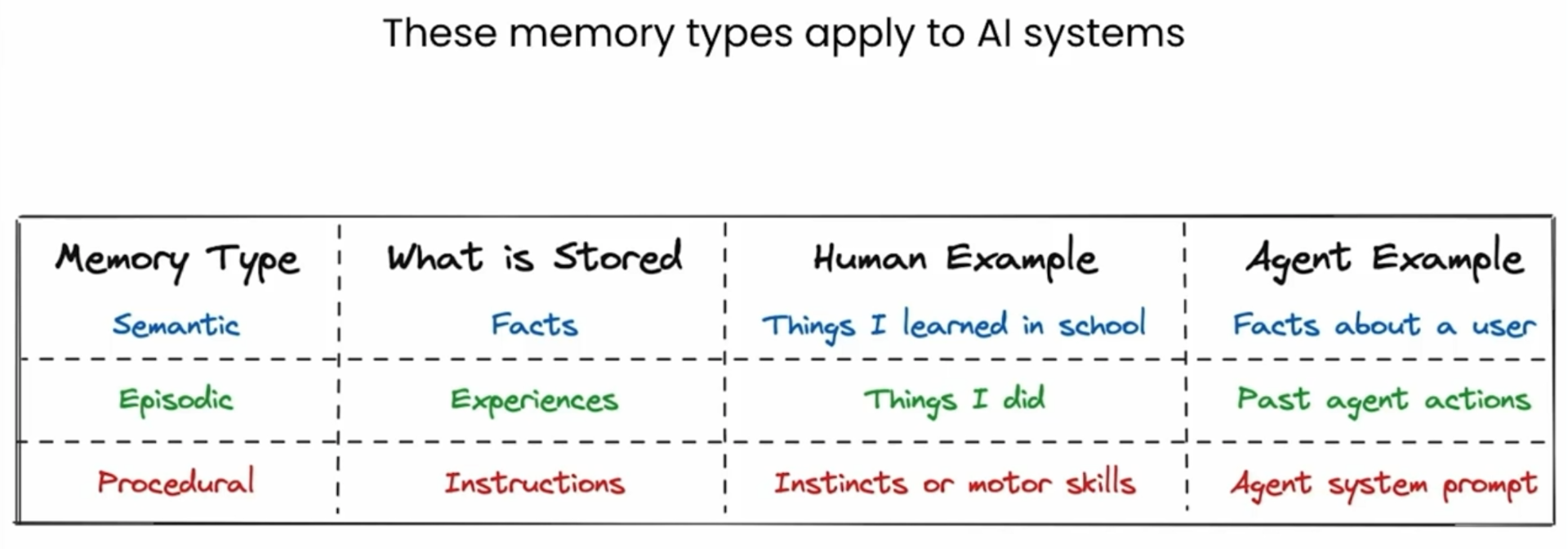
当在Store中存储对象(例如内存)时,我们提供:
-
对象的命名空间,一个元组(类似于目录)。
- 对象的键(类似于文件名)
- 对象值(与文件内容类似)。
- 我们使用put方法通过命名空间和键将对象保存到store中。
# Namespace for the memory to save
user_id = "1"
namespace_for_memory = (user_id, "memories")
# Save a memory to namespace as key and value
key = str(uuid.uuid4())
# The value needs to be a dictionary
value = {"food_preference" : "I like pizza"}
# Save the memory
in_memory_store.put(namespace_for_memory, key, value)
我们使用search通过namespace从store中检索对象。这将返回一个列表。
# Search
memories = in_memory_store.search(namespace_for_memory)
print(type(memories))
# Metatdata
print(memories[0].dict())
# The key, value
print(memories[0].key, memories[0].value)
# 我们也可以使用get方法通过命名空间和键来取得对象。
# Get the memory by namespace and key
memory = in_memory_store.get(namespace_for_memory, key)
print(memory.dict())
输出
<class 'list'>
{'namespace': ['1', 'memories'], 'key': '3fbd1852-ac50-4459-b4d2-c7ec31c6aa5b', 'value': {'food_preference': 'I like pizza'}, 'created_at': '2025-05-15T06:26:40.366310+00:00', 'updated_at': '2025-05-15T06:26:40.366608+00:00', 'score': None}
3fbd1852-ac50-4459-b4d2-c7ec31c6aa5b {'food_preference': 'I like pizza'}
{'namespace': ['1', 'memories'], 'key': '3fbd1852-ac50-4459-b4d2-c7ec31c6aa5b', 'value': {'food_preference': 'I like pizza'}, 'created_at': '2025-05-15T06:26:40.366310+00:00', 'updated_at': '2025-05-15T06:26:40.366608+00:00'}
Chatbot with long-term memory
我们想要一个具有两种内存类型的聊天机器人:
短期(线程内)内存:聊天机器人可以保留对话历史记录和/或允许聊天会话中断。长期(跨线程)内存:聊天机器人可以在所有聊天会话中记住特定用户的信息。
对于短期记忆,我们将使用checkpointer。
有关checkpointer的更多信息,请参阅模块2和我们的概念文档,但总结如下:
- 它们在每个步骤将图状态写入线程。
- 他们将聊天记录保存在线程中。
- 它们允许图形被中断和/或从线程中的任何步骤恢复。
对于长期记忆,我们将使用上面介绍的LangGraph存储。
-
聊天历史记录将使用checkpointer保存到短期内存中。聊天机器人将反思聊天历史。
-
然后,它将创建一个内存并将其保存到LangGraph Store存储中。
-
在未来的聊天会话中可以访问此内存,以个性化聊天机器人的响应。
module5/store.py
from IPython.display import Image, display
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import StateGraph, MessagesState, START, END
from langgraph.store.base import BaseStore
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.runnables.config import RunnableConfig
# Chatbot instruction
MODEL_SYSTEM_MESSAGE = """You are a helpful assistant with memory that provides information about the user.
If you have memory for this user, use it to personalize your responses.
Here is the memory (it may be empty): {memory}"""
# Create new memory from the chat history and any existing memory
CREATE_MEMORY_INSTRUCTION = """"You are collecting information about the user to personalize your responses.
CURRENT USER INFORMATION:
{memory}
INSTRUCTIONS:
1. Review the chat history below carefully
2. Identify new information about the user, such as:
- Personal details (name, location)
- Preferences (likes, dislikes)
- Interests and hobbies
- Past experiences
- Goals or future plans
3. Merge any new information with existing memory
4. Format the memory as a clear, bulleted list
5. If new information conflicts with existing memory, keep the most recent version
Remember: Only include factual information directly stated by the user. Do not make assumptions or inferences.
Based on the chat history below, please update the user information:"""
def call_model(state: MessagesState, config: RunnableConfig, store: BaseStore):
"""Load memory from the store and use it to personalize the chatbot's response."""
# Get the user ID from the config
user_id = config["configurable"]["user_id"]
# Retrieve memory from the store
namespace = ("memory", user_id)
key = "user_memory"
existing_memory = store.get(namespace, key)
# Extract the actual memory content if it exists and add a prefix
if existing_memory:
# Value is a dictionary with a memory key
existing_memory_content = existing_memory.value.get('memory')
else:
existing_memory_content = "No existing memory found."
# Format the memory in the system prompt
system_msg = MODEL_SYSTEM_MESSAGE.format(memory=existing_memory_content)
# Respond using memory as well as the chat history
response = model.invoke([SystemMessage(content=system_msg)]+state["messages"])
return {"messages": response}
def write_memory(state: MessagesState, config: RunnableConfig, store: BaseStore):
"""Reflect on the chat history and save a memory to the store."""
# Get the user ID from the config
user_id = config["configurable"]["user_id"]
# Retrieve existing memory from the store
namespace = ("memory", user_id)
existing_memory = store.get(namespace, "user_memory")
# Extract the memory
if existing_memory:
existing_memory_content = existing_memory.value.get('memory')
else:
existing_memory_content = "No existing memory found."
# Format the memory in the system prompt
system_msg = CREATE_MEMORY_INSTRUCTION.format(memory=existing_memory_content)
new_memory = model.invoke([SystemMessage(content=system_msg)]+state['messages'])
# Overwrite the existing memory in the store
key = "user_memory"
# Write value as a dictionary with a memory key
store.put(namespace, key, {"memory": new_memory.content})
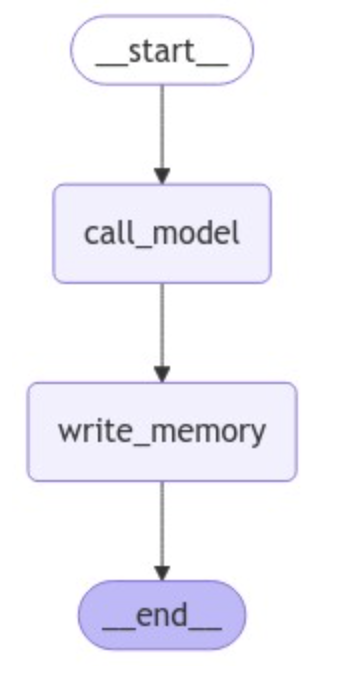
# Define the graph
builder = StateGraph(MessagesState)
builder.add_node("call_model", call_model)
builder.add_node("write_memory", write_memory)
builder.add_edge(START, "call_model")
builder.add_edge("call_model", "write_memory")
builder.add_edge("write_memory", END)
# Store for long-term (across-thread) memory
across_thread_memory = InMemoryStore()
# Checkpointer for short-term (within-thread) memory
within_thread_memory = MemorySaver()
# Compile the graph with the checkpointer fir and store
graph = builder.compile(checkpointer=within_thread_memory, store=across_thread_memory)
当我们与聊天机器人交互时,我们提供两个东西:
Short-term (within-thread) memory:用于保存聊天历史记录的thread ID。Long-term (cross-thread) memory:用user ID命名用户的长期记忆。
让我们看看这些在实践中是如何一起工作的。
# We supply a thread ID for short-term (within-thread) memory
# We supply a user ID for long-term (across-thread) memory
config = {"configurable": {"thread_id": "1", "user_id": "1"}}
# User input
input_messages = [HumanMessage(content="Hi, my name is Lance")]
# Run the graph
for chunk in graph.stream({"messages": input_messages}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
================================ Human Message =================================
Hi, my name is Lance
================================== Ai Message ==================================
Hello, Lance! It's nice to meet you. How can I assist you today?
# User input
input_messages = [HumanMessage(content="I like to bike around San Francisco")]
# Run the graph
for chunk in graph.stream({"messages": input_messages}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
================================ Human Message =================================
I like to bike around San Francisco
================================== Ai Message ==================================
That sounds like a great way to explore the city, Lance! San Francisco has some beautiful routes and views. Do you have a favorite trail or area you like to bike in?
我们使用MemorySaver检查指针来处理线程内内存。这会将聊天历史记录保存到线程。我们可以查看保存到该线程的聊天历史记录。
thread = {"configurable": {"thread_id": "1"}}
state = graph.get_state(thread).values
for m in state["messages"]:
m.pretty_print()
================================ Human Message =================================
Hi, my name is Lance
================================== Ai Message ==================================
Hello, Lance! It's nice to meet you. How can I assist you today?
================================ Human Message =================================
I like to bike around San Francisco
================================== Ai Message ==================================
That sounds like a great way to explore the city, Lance! San Francisco has some beautiful routes and views. Do you have a favorite trail or area you like to bike in?
回想一下,我们使用store编译了图表:
across_thread_memory = InMemoryStore()
并且,我们向图中添加了一个节点(write_memory),它反映了聊天历史并将内存保存到store。
我们可以看看内存是否保存到了store中。
# Namespace for the memory to save
user_id = "1"
namespace = ("memory", user_id)
existing_memory = across_thread_memory.get(namespace, "user_memory")
existing_memory.dict()
{'value': {'memory': "**Updated User Information:**\n- User's name is Lance.\n- Likes to bike around San Francisco."},
'key': 'user_memory',
'namespace': ['memory', '1'],
'created_at': '2024-11-05T00:12:17.383918+00:00',
'updated_at': '2024-11-05T00:12:25.469528+00:00'}
现在,让我们用相同的用户ID创建一个新线程。
我们应该看到聊天机器人记住了用户的个人资料,并使用它来个性化响应。
# We supply a user ID for across-thread memory as well as a new thread ID
config = {"configurable": {"thread_id": "2", "user_id": "1"}}
# User input
input_messages = [HumanMessage(content="Hi! Where would you recommend that I go biking?")]
# Run the graph
for chunk in graph.stream({"messages": input_messages}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
================================ Human Message =================================
Hi! Where would you recommend that I go biking?
================================== Ai Message ==================================
Hi Lance! Since you enjoy biking around San Francisco, there are some fantastic routes you might love. Here are a few recommendations:
1. **Golden Gate Park**: This is a classic choice with plenty of trails and beautiful scenery. You can explore the park's many attractions, like the Conservatory of Flowers and the Japanese Tea Garden.
2. **The Embarcadero**: A ride along the Embarcadero offers stunning views of the Bay Bridge and the waterfront. It's a great way to experience the city's vibrant atmosphere.
3. **Marin Headlands**: If you're up for a bit of a challenge, biking across the Golden Gate Bridge to the Marin Headlands offers breathtaking views of the city and the Pacific Ocean.
4. **Presidio**: This area has a network of trails with varying difficulty levels, and you can enjoy views of the Golden Gate Bridge and the bay.
5. **Twin Peaks**: For a more challenging ride, head up to Twin Peaks. The climb is worth it for the panoramic views of the city.
Let me know if you want more details on any of these routes!
# User input
input_messages = [HumanMessage(content="Great, are there any bakeries nearby that I can check out? I like a croissant after biking.")]
# Run the graph
for chunk in graph.stream({"messages": input_messages}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
================================ Human Message =================================
Great, are there any bakeries nearby that I can check out? I like a croissant after biking.
================================== Ai Message ==================================
Absolutely, Lance! Here are a few bakeries in San Francisco where you can enjoy a delicious croissant after your ride:
1. **Tartine Bakery**: Located in the Mission District, Tartine is famous for its pastries, and their croissants are a must-try.
2. **Arsicault Bakery**: This bakery in the Richmond District has been praised for its buttery, flaky croissants. It's a bit of a detour, but worth it!
3. **b. Patisserie**: Situated in Lower Pacific Heights, b. Patisserie offers a variety of pastries, and their croissants are particularly popular.
4. **Le Marais Bakery**: With locations in the Marina and Castro, Le Marais offers a charming French bakery experience with excellent croissants.
5. **Neighbor Bakehouse**: Located in the Dogpatch, this bakery is known for its creative pastries, including some fantastic croissants.
These spots should provide a delightful treat after your biking adventures. Enjoy your ride and your croissant!
Chatbot with Profile Schema
我们介绍了LangGraph记忆存储,它是一种保存和检索长期记忆的方法。
我们构建了一个简单的聊天机器人,它同时使用短期(线程内)和长期(跨线程)内存。
它保存了长期的语义记忆(关于用户的事实)“在热路径中”,因为用户正在与它聊天。
我们的聊天机器人将内存保存为字符串。在实践中,我们通常希望记忆有一个结构。例如,记忆可以是一个单一的、不断更新的模式。
在我们的例子中,我们希望这是一个单一的用户配置文件。我们将扩展我们的聊天机器人,将语义记忆保存到单个用户配置文件。
我们还将引入一个库Trustcall,用于使用新信息更新此模式。
Defining a user profile schema
Python有许多不同的结构化数据类型,例如TypedDict、字典、JSON和Pydantic。
让我们从使用TypedDict来定义用户配置文件模式开始。
from typing import TypedDict, List
class UserProfile(TypedDict):
"""User profile schema with typed fields"""
user_name: str # The user's preferred name
interests: List[str] # A list of the user's interests
Saving a schema to the store
LangGraph存储可以接受任何Python字典作为值。
# TypedDict instance
user_profile: UserProfile = {
"user_name": "Lance",
"interests": ["biking", "technology", "coffee"]
}
user_profile
{'user_name': 'Lance', 'interests': ['biking', 'technology', 'coffee']}
我们使用put方法将TypedDict保存到store中。
import uuid
from langgraph.store.memory import InMemoryStore
# Initialize the in-memory store
in_memory_store = InMemoryStore()
# Namespace for the memory to save
user_id = "1"
namespace_for_memory = (user_id, "memory")
# Save a memory to namespace as key and value
key = "user_profile"
value = user_profile
in_memory_store.put(namespace_for_memory, key, value)
Chatbot with profile schema
LangChain的chat模型接口有一个with_structured_output方法来强制结构化输出。
当我们想要强制输出符合模式时,它很有用,并为我们解析输出。
from pydantic import BaseModel, Field
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
# Initialize the model
model = ChatOpenAI(model="gpt-4o", temperature=0)
# Bind schema to model
model_with_structure = model.with_structured_output(UserProfile)
# Invoke the model to produce structured output that matches the schema
structured_output = model_with_structure.invoke([HumanMessage("My name is Lance, I like to bike.")])
structured_output
{'user_name': 'Lance', 'interests': ['biking']}
现在,让我们将它用于我们的聊天机器人。这只需要对write_memory函数做一些微小的修改。
我们使用上面定义的model_with_structure来生成与我们的模式匹配的配置文件。
module5/memory-schema-profile.py
from IPython.display import Image, display
from langgraph.checkpoint.memory import MemorySaver
from langgraph.graph import StateGraph, MessagesState, START, END
from langgraph.store.base import BaseStore
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
from langchain_core.runnables.config import RunnableConfig
# Chatbot instruction
MODEL_SYSTEM_MESSAGE = """You are a helpful assistant with memory that provides information about the user.
If you have memory for this user, use it to personalize your responses.
Here is the memory (it may be empty): {memory}"""
# Create new memory from the chat history and any existing memory
CREATE_MEMORY_INSTRUCTION = """Create or update a user profile memory based on the user's chat history.
This will be saved for long-term memory. If there is an existing memory, simply update it.
Here is the existing memory (it may be empty): {memory}"""
def call_model(state: MessagesState, config: RunnableConfig, store: BaseStore):
"""Load memory from the store and use it to personalize the chatbot's response."""
# Get the user ID from the config
user_id = config["configurable"]["user_id"]
# Retrieve memory from the store
namespace = ("memory", user_id)
existing_memory = store.get(namespace, "user_memory")
# Format the memories for the system prompt
if existing_memory and existing_memory.value:
memory_dict = existing_memory.value
formatted_memory = (
f"Name: {memory_dict.get('user_name', 'Unknown')}\n"
f"Interests: {', '.join(memory_dict.get('interests', []))}"
)
else:
formatted_memory = None
# Format the memory in the system prompt
system_msg = MODEL_SYSTEM_MESSAGE.format(memory=formatted_memory)
# Respond using memory as well as the chat history
response = model.invoke([SystemMessage(content=system_msg)]+state["messages"])
return {"messages": response}
def write_memory(state: MessagesState, config: RunnableConfig, store: BaseStore):
"""Reflect on the chat history and save a memory to the store."""
# Get the user ID from the config
user_id = config["configurable"]["user_id"]
# Retrieve existing memory from the store
namespace = ("memory", user_id)
existing_memory = store.get(namespace, "user_memory")
# Format the memories for the system prompt
if existing_memory and existing_memory.value:
memory_dict = existing_memory.value
formatted_memory = (
f"Name: {memory_dict.get('user_name', 'Unknown')}\n"
f"Interests: {', '.join(memory_dict.get('interests', []))}"
)
else:
formatted_memory = None
# Format the existing memory in the instruction
system_msg = CREATE_MEMORY_INSTRUCTION.format(memory=formatted_memory)
# Invoke the model to produce structured output that matches the schema
new_memory = model_with_structure.invoke([SystemMessage(content=system_msg)]+state['messages'])
# Overwrite the existing use profile memory
key = "user_memory"
store.put(namespace, key, new_memory)
# Define the graph
builder = StateGraph(MessagesState)
builder.add_node("call_model", call_model)
builder.add_node("write_memory", write_memory)
builder.add_edge(START, "call_model")
builder.add_edge("call_model", "write_memory")
builder.add_edge("write_memory", END)
# Store for long-term (across-thread) memory
across_thread_memory = InMemoryStore()
# Checkpointer for short-term (within-thread) memory
within_thread_memory = MemorySaver()
# Compile the graph with the checkpointer fir and store
graph = builder.compile(checkpointer=within_thread_memory, store=across_thread_memory)
# View
display(Image(graph.get_graph(xray=1).draw_mermaid_png()))
# We supply a thread ID for short-term (within-thread) memory
# We supply a user ID for long-term (across-thread) memory
config = {"configurable": {"thread_id": "1", "user_id": "1"}}
# User input
input_messages = [HumanMessage(content="Hi, my name is Lance and I like to bike around San Francisco and eat at bakeries.")]
# Run the graph
for chunk in graph.stream({"messages": input_messages}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
================================ Human Message =================================
Hi, my name is Lance and I like to bike around San Francisco and eat at bakeries.
================================== Ai Message ==================================
Hi Lance! It's great to meet you. Biking around San Francisco sounds like a fantastic way to explore the city, and there are so many amazing bakeries to try. Do you have any favorite bakeries or biking routes in the city?
让我们检查一下存储中的内存。
我们可以看到内存是一个与我们的模式匹配的字典。
# Namespace for the memory to save
user_id = "1"
namespace = ("memory", user_id)
existing_memory = across_thread_memory.get(namespace, "user_memory")
existing_memory.value
什么时候会失败
with_structured_output非常有用,但如果我们使用更复杂的模式会发生什么?
下面是一个更复杂的模式示例,我们将在下面测试它。
这是一个Pydantic模型,描述了用户对交流和信任的偏好。
module5/output.py
from typing import List, Optional
from pydantic import BaseModel, Field
class OutputFormat(BaseModel):
preference: str
sentence_preference_revealed: str
class TelegramPreferences(BaseModel):
preferred_encoding: Optional[List[OutputFormat]] = None
favorite_telegram_operators: Optional[List[OutputFormat]] = None
preferred_telegram_paper: Optional[List[OutputFormat]] = None
class MorseCode(BaseModel):
preferred_key_type: Optional[List[OutputFormat]] = None
favorite_morse_abbreviations: Optional[List[OutputFormat]] = None
class Semaphore(BaseModel):
preferred_flag_color: Optional[List[OutputFormat]] = None
semaphore_skill_level: Optional[List[OutputFormat]] = None
class TrustFallPreferences(BaseModel):
preferred_fall_height: Optional[List[OutputFormat]] = None
trust_level: Optional[List[OutputFormat]] = None
preferred_catching_technique: Optional[List[OutputFormat]] = None
class CommunicationPreferences(BaseModel):
telegram: TelegramPreferences
morse_code: MorseCode
semaphore: Semaphore
class UserPreferences(BaseModel):
communication_preferences: CommunicationPreferences
trust_fall_preferences: TrustFallPreferences
class TelegramAndTrustFallPreferences(BaseModel):
pertinent_user_preferences: UserPreferences
现在,让我们尝试使用with_structured_output方法提取此模式。
from pydantic import ValidationError
# Bind schema to model
model_with_structure = model.with_structured_output(TelegramAndTrustFallPreferences)
# Conversation
conversation = """Operator: How may I assist with your telegram, sir?
Customer: I need to send a message about our trust fall exercise.
Operator: Certainly. Morse code or standard encoding?
Customer: Morse, please. I love using a straight key.
Operator: Excellent. What's your message?
Customer: Tell him I'm ready for a higher fall, and I prefer the diamond formation for catching.
Operator: Done. Shall I use our "Daredevil" paper for this daring message?
Customer: Perfect! Send it by your fastest carrier pigeon.
Operator: It'll be there within the hour, sir."""
# Invoke the model
try:
model_with_structure.invoke(f"""Extract the preferences from the following conversation:
<convo>
{conversation}
</convo>""")
except ValidationError as e:
print(e)
执行会遇到输出错误
1 validation error for TelegramAndTrustFallPreferences
pertinent_user_preferences
Field required [type=missing, input_value={'preferences': {'encodin...ormation for catching'}}, input_type=dict]
For further information visit https://errors.pydantic.dev/2.11/v/missing
用于创建和更新概要模式的Trustcall
我们可以看到,处理模式(schema)是件棘手的事。复杂的模式提取起来难度较大。而且,即使是更新简单的模式也会带来挑战。
以我们之前的聊天机器人(chatbot)为例。每次我们选择保存新的记忆(memory)时,都会从头开始重新生成用户画像(profile schema)。这种做法效率低下,如果模式包含大量信息,每次重新生成都可能会浪费模型的令牌(model tokens)。
更糟糕的是,从头重新生成用户画像时,我们可能会丢失信息。而解决这些问题正是 TrustCall 的动力所在!
TrustCall 是由 LangChain 团队的 Will Fu-Hinthorn 开发的一个开源库,用于更新 JSON 模式。
它正是为了解决在处理记忆(memory)时遇到的这些挑战而诞生的。
接下来,我们先来展示一下在处理这条消息列表时,如何使用 TrustCall 进行简单的提取操作。
# Conversation
conversation = [HumanMessage(content="Hi, I'm Lance."),
AIMessage(content="Nice to meet you, Lance."),
HumanMessage(content="I really like biking around San Francisco.")]
我们使用create_extractor,将模型和模式作为工具传入。通过TrustCall,可以以多种方式提供模式。例如,我们可以传递一个JSON对象/ Python字典或Pydantic模型。
在底层,TrustCall使用tool calling从message的输入列表中产生结构化输出。为了强制Trustcall生成结构化输出,我们可以在tool_choice参数中包含模式名称。
我们可以通过上面的对话调用extractor。
from trustcall import create_extractor
# Schema
class UserProfile(BaseModel):
"""User profile schema with typed fields"""
user_name: str = Field(description="The user's preferred name")
interests: List[str] = Field(description="A list of the user's interests")
# Initialize the model
model = ChatOpenAI(model="gpt-4o", temperature=0)
# Create the extractor
trustcall_extractor = create_extractor(
model,
tools=[UserProfile],
tool_choice="UserProfile"
)
# Instruction
system_msg = "Extract the user profile from the following conversation"
# Invoke the extractor
result = trustcall_extractor.invoke({"messages": [SystemMessage(content=system_msg)]+conversation})
当我们调用extractor时,我们会得到以下信息:
messages:包含工具调用的AIMessages列表。responses:解析后的工具调用与我们的模式匹配。response_metadata:适用于更新现有工具调用。它指出哪个响应对应于哪个现有对象。
注意:参考trustcall文档,不能在ChatOpenAI模型初始化时使用json_schema
def modelResJson(): model = ChatOpenAI( api_key="xxxx", base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", model="qwen-max", model_kwargs={ "response_format": {"type": "json_object"} # 导致错误 } ) return model否则,报错
```python lib/python3.12/site-packages/openai/lib/_parsing/_completions.py”, line 53, in validate_input_tools raise ValueError( ValueError:
UserProfileis not strict. Onlystrictfunction tools can be auto-parsed
完整代码module5/TrustCall.py
import sys
import os
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
from trustcall import create_extractor
from pydantic import BaseModel, Field, ConfigDict
from typing import List
class UserProfile(BaseModel):
user_name: str = Field(description="The user's preferred name")
interests: List[str] = Field(description="A list of the user's interests")
import common.customModel
model = common.customModel.customModel()
# Create the extractor
trustcall_extractor = create_extractor(
model,
tools=[UserProfile],
tool_choice="UserProfile"
)
# Instruction
system_msg = "Extract the user profile from the following conversation"
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
# Conversation
conversation = [
HumanMessage(content="Hi, I'm Lance."),
AIMessage(content="Nice to meet you, Lance."),
HumanMessage(content="I really like biking around San Francisco.")
]
# Invoke the extractor
result = trustcall_extractor.invoke({"messages": [SystemMessage(content=system_msg)] + conversation})
for m in result["messages"]:
m.pretty_print()
from common.log import debug,info,error
schema = result["responses"]
debug(f"schema:{schema}")
dump = schema[0].model_dump()
debug(f"dump:{dump}")
response_metadata = result["response_metadata"]
debug(f"response_metadata:{response_metadata}")
输出
================================== Ai Message ==================================
Tool Calls:
UserProfile (call_9c620d8aae89483fb6222a)
Call ID: call_9c620d8aae89483fb6222a
Args:
user_name: Lance
interests: ['biking around San Francisco']
[2025-05-19 17:39:30] [DEBUG] [/Users/kaijin/Documents/AI_ML/workspace/langgraph/langchain-academy/lc-academy-env/common/log.py:debug] schema:[UserProfile(user_name='Lance', interests=['biking around San Francisco'])]
[2025-05-19 17:39:30] [DEBUG] [/Users/kaijin/Documents/AI_ML/workspace/langgraph/langchain-academy/lc-academy-env/common/log.py:debug] dump:{'user_name': 'Lance', 'interests': ['biking around San Francisco']}
[2025-05-19 17:39:30] [DEBUG] [/Users/kaijin/Documents/AI_ML/workspace/langgraph/langchain-academy/lc-academy-env/common/log.py:debug] response_metadata:[{'id': 'call_9c620d8aae89483fb6222a'}]
让我们看看如何使用它来更新配置文件。
为了更新,TrustCall接受一组消息以及现有的模式(schema)。核心思想是它提示模型生成一个JSON补丁,只更新模式的相关部分。
与简单地覆盖整个模式相比,这样做不太容易出错。由于模型只需要生成模式中发生变化的部分,因此它也更高效。
我们可以将现有模式保存为dict。使用model_dump()将Pydantic模型实例序列化为dict。将它和模式名称UserProfile一起传递给"existing"参数。
# Update the conversation
updated_conversation = [HumanMessage(content="Hi, I'm Lance."),
AIMessage(content="Nice to meet you, Lance."),
HumanMessage(content="I really like biking around San Francisco."),
AIMessage(content="San Francisco is a great city! Where do you go after biking?"),
HumanMessage(content="I really like to go to a bakery after biking."),]
# Update the instruction
system_msg = f"""Update the memory (JSON doc) to incorporate new information from the following conversation"""
# Invoke the extractor with the updated instruction and existing profile with the corresponding tool name (UserProfile)
result = trustcall_extractor.invoke({"messages": [SystemMessage(content=system_msg)]+updated_conversation},
{"existing": {"UserProfile": schema[0].model_dump()}})
这里的 “existing” 参数对结果有重要影响:
-
“existing” 参数用于提供已有的用户信息,让模型知道之前已经提取过什么信息,它包含了一个字典,其中键是工具名称(这里是 “UserProfile”),值是该工具之前生成的结果
-
从输出结果可以看到,模型成功地将新的信息(”visiting bakeries”)添加到了已有的兴趣列表中,最终结果变成了:interests=[‘biking’, ‘visiting bakeries’],如果没有 “existing” 参数,模型可能会重新开始提取,而不是基于已有信息进行更新
-
从trustcall代码实现来看,”existing” 是一个固定的参数名,它是 TrustCall 框架的 API 约定,这个参数名是在框架层面定义的,不是由 LLM 直接处理的
Trustcall核心原理
trustcall的核心原理是”patch-don’t-post”(打补丁而非重新生成)策略,它通过使用JSON补丁操作(JSON Patch operations)来解决LLM生成或修改复杂JSON结构的问题。
主要问题和解决方案
trustcall解决了LLM在生成结构化输出时面临的两个主要挑战:
- 填充复杂嵌套的JSON模式(schema)
- 更新现有模式而不丢失信息 README.md:31-35
传统方法通常要求LLM一次性生成完整的JSON结构,这容易导致错误。trustcall不同之处在于,它使用了JSON补丁(JSONPatch)来进行增量更新。
核心工作流程
trustcall的工作流程包括以下几个关键步骤:
- 初始提取:LLM尝试基于提供的模式生成结构化输出
- 验证:输出通过ValidationNode验证是否符合模式要求
- 错误修复:如果验证失败,不会重新生成整个输出,而是生成JSON补丁来修复特定错误
- 更新现有模式:针对已有数据,仅生成需要修改部分的补丁
这个过程通过一个状态图(StateGraph)来管理,它会跟踪尝试次数并可以重试到可配置的最大值
关键组件
- ValidationNode:负责验证工具调用是否符合模式要求,并提供错误信息
- ExtractUpdates:专门处理使用JSON补丁更新现有模式的组件。它的独特之处在于只关注发生变化的部分
- PatchDoc和PatchFunctionErrors:用于生成和应用JSON补丁的工具
主要优势
使用这种方法带来几个显著的好处:
- 更有效率:只需重新生成需要修复的部分,节省token消耗
- 更可靠:减少了意外丢失信息的风险
- 适应复杂模式:能够处理深度嵌套的复杂JSON结构
- 无损更新:可以更新现有数据而不丢失其他信息 README.md:765-794
实现机制
内部实现使用了一个基于节点的工作流,通过状态图管理执行流程。核心创建函数create_extractor设置了整个提取流程
对于验证失败的情况,而不是简单地重试,trustcall会使用补丁修复具体的错误
Chatbot with profile schema updating
现在,让我们将Trustcall引入到我们的聊天机器人中来创建和更新内存配置文件(profile)。
module5/TrustCall2.py
from IPython.display import Image, display
from langchain_core.messages import HumanMessage, SystemMessage
from langgraph.graph import StateGraph, MessagesState, START, END
from langchain_core.runnables.config import RunnableConfig
from langgraph.checkpoint.memory import MemorySaver
from langgraph.store.base import BaseStore
# Initialize the model
model = ChatOpenAI(model="gpt-4o", temperature=0)
# Schema
class UserProfile(BaseModel):
""" Profile of a user """
user_name: str = Field(description="The user's preferred name")
user_location: str = Field(description="The user's location")
interests: list = Field(description="A list of the user's interests")
# Create the extractor
trustcall_extractor = create_extractor(
model,
tools=[UserProfile],
tool_choice="UserProfile", # Enforces use of the UserProfile tool
)
# Chatbot instruction
MODEL_SYSTEM_MESSAGE = """You are a helpful assistant with memory that provides information about the user.
If you have memory for this user, use it to personalize your responses.
Here is the memory (it may be empty): {memory}"""
# Extraction instruction
TRUSTCALL_INSTRUCTION = """Create or update the memory (JSON doc) to incorporate information from the following conversation:"""
def call_model(state: MessagesState, config: RunnableConfig, store: BaseStore):
"""Load memory from the store and use it to personalize the chatbot's response."""
# Get the user ID from the config
user_id = config["configurable"]["user_id"]
# Retrieve memory from the store
namespace = ("memory", user_id)
existing_memory = store.get(namespace, "user_memory")
# Format the memories for the system prompt
if existing_memory and existing_memory.value:
memory_dict = existing_memory.value
formatted_memory = (
f"Name: {memory_dict.get('user_name', 'Unknown')}\n"
f"Location: {memory_dict.get('user_location', 'Unknown')}\n"
f"Interests: {', '.join(memory_dict.get('interests', []))}"
)
else:
formatted_memory = None
# Format the memory in the system prompt
system_msg = MODEL_SYSTEM_MESSAGE.format(memory=formatted_memory)
# Respond using memory as well as the chat history
response = model.invoke([SystemMessage(content=system_msg)]+state["messages"])
return {"messages": response}
def write_memory(state: MessagesState, config: RunnableConfig, store: BaseStore):
"""Reflect on the chat history and save a memory to the store."""
# Get the user ID from the config
user_id = config["configurable"]["user_id"]
# Retrieve existing memory from the store
namespace = ("memory", user_id)
existing_memory = store.get(namespace, "user_memory")
# Get the profile as the value from the list, and convert it to a JSON doc
existing_profile = {"UserProfile": existing_memory.value} if existing_memory else None
# Invoke the extractor
result = trustcall_extractor.invoke({"messages": [SystemMessage(content=TRUSTCALL_INSTRUCTION)]+state["messages"], "existing": existing_profile})
# Get the updated profile as a JSON object
updated_profile = result["responses"][0].model_dump()
# Save the updated profile
key = "user_memory"
store.put(namespace, key, updated_profile)
# Define the graph
builder = StateGraph(MessagesState)
builder.add_node("call_model", call_model)
builder.add_node("write_memory", write_memory)
builder.add_edge(START, "call_model")
builder.add_edge("call_model", "write_memory")
builder.add_edge("write_memory", END)
# Store for long-term (across-thread) memory
across_thread_memory = InMemoryStore()
# Checkpointer for short-term (within-thread) memory
within_thread_memory = MemorySaver()
# Compile the graph with the checkpointer fir and store
graph = builder.compile(checkpointer=within_thread_memory, store=across_thread_memory)
# View
display(Image(graph.get_graph(xray=1).draw_mermaid_png()))
# We supply a thread ID for short-term (within-thread) memory
# We supply a user ID for long-term (across-thread) memory
config = {"configurable": {"thread_id": "1", "user_id": "1"}}
# User input
input_messages = [HumanMessage(content="Hi, my name is Lance")]
# Run the graph
for chunk in graph.stream({"messages": input_messages}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
================================ Human Message =================================
Hi, my name is Lance
================================== Ai Message ==================================
Hello, Lance! It's nice to meet you. How can I assist you today?
# User input
input_messages = [HumanMessage(content="I like to bike around San Francisco")]
# Run the graph
for chunk in graph.stream({"messages": input_messages}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
================================ Human Message =================================
I like to bike around San Francisco
================================== Ai Message ==================================
That sounds like a great way to explore the city! San Francisco has some beautiful routes and views. Do you have any favorite trails or spots you like to visit while biking?
# Namespace for the memory to save
user_id = "1"
namespace = ("memory", user_id)
existing_memory = across_thread_memory.get(namespace, "user_memory")
existing_memory.dict()
{'value': {'user_name': 'Lance',
'user_location': 'San Francisco',
'interests': ['biking']},
'key': 'user_memory',
'namespace': ['memory', '1'],
'created_at': '2024-11-04T23:51:17.662428+00:00',
'updated_at': '2024-11-04T23:51:41.697652+00:00'}
# The user profile saved as a JSON object
existing_memory.value
{'user_name': 'Lance',
'user_location': 'San Francisco',
'interests': ['biking']}
# User input
input_messages = [HumanMessage(content="I also enjoy going to bakeries")]
# Run the graph
for chunk in graph.stream({"messages": input_messages}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
================================ Human Message =================================
I also enjoy going to bakeries
================================== Ai Message ==================================
Biking and visiting bakeries sounds like a delightful combination! San Francisco has some fantastic bakeries. Do you have any favorites, or are you looking for new recommendations to try out?
用新的话题继续对话。
# We supply a thread ID for short-term (within-thread) memory
# We supply a user ID for long-term (across-thread) memory
config = {"configurable": {"thread_id": "2", "user_id": "1"}}
# User input
input_messages = [HumanMessage(content="What bakeries do you recommend for me?")]
# Run the graph
for chunk in graph.stream({"messages": input_messages}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
================================ Human Message =================================
What bakeries do you recommend for me?
================================== Ai Message ==================================
Since you're in San Francisco and enjoy going to bakeries, here are a few recommendations you might like:
1. **Tartine Bakery** - Known for its delicious bread and pastries, it's a must-visit for any bakery enthusiast.
2. **B. Patisserie** - Offers a delightful selection of French pastries, including their famous kouign-amann.
3. **Arsicault Bakery** - Renowned for its croissants, which have been praised as some of the best in the country.
4. **Craftsman and Wolves** - Known for their inventive pastries and the "Rebel Within," a savory muffin with a soft-cooked egg inside.
5. **Mr. Holmes Bakehouse** - Famous for their cruffins and other creative pastries.
These spots should offer a great variety of treats for you to enjoy. Happy bakery hopping!